from gensim.test.utils import common_texts
from gensim.models import Word2Vec
model = Word2Vec(sentences=common_texts, vector_size=100, window=5, min_count=1, workers=4)
model.save("word2vec.model")16 Deep Learning模型应用
Qiu et al. (2020)
One of the advantages of these neural models is their ability to alleviate the feature engineering problem.
Non-neural NLP methods usually heavily rely on the discrete handcrafted features, while neural methods usually use low-dimensional and dense vectors (aka. distributed representation) to implicitly represent the syntactic or semantic features of the language. These representations are learned in specific NLP tasks. Therefore, neural methods make it easy for people to develop various NLP systems.
16.1 Vectorize
- 基于
one-hot、tf-idf、textrank等的bag-of-words; - 主题模型:
LSA(SVD)、pLSA、LDA; - 基于词向量的固定表征:
word2vec、fastText、glove - 基于词向量的动态表征:
elmo、GPT、bert
16.1.1 word2vec
word2vec in Gensim
https://radimrehurek.com/gensim/models/word2vec.html
训练完的模型可以继续训练:
model = Word2Vec.load("word2vec.model")
model.train([["hello", "world"]], total_examples=1, epochs=1)(0, 2)vector = model.wv['computer'] # get numpy vector of a word
sims = model.wv.most_similar('computer', topn=10) # get other similar words
sims[('system', 0.21617139875888824),
('survey', 0.044689226895570755),
('interface', 0.015203381888568401),
('time', 0.0019510718993842602),
('trees', -0.03284316509962082),
('human', -0.07424270361661911),
('response', -0.09317589551210403),
('graph', -0.09575341641902924),
('eps', -0.10513808578252792),
('user', -0.16911622881889343)]16.1.2 Doc2vec
https://radimrehurek.com/gensim/auto_examples/tutorials/run_doc2vec_lee.html#doc2vec-model
16.2 Hugging Face 介绍
16.3 Transformer 组件基本用法
https://www.cnblogs.com/zjuhaohaoxuexi/p/16989178.html
Transformers库将目前的NLP任务归纳为以下几类:
- 文本分类:例如情感分析、句子对关系判断等;
- 对文本中的词语进行分类:例如词性标注 (POS)、命名实体识别 (NER)等;
- 文本生成:例如填充预设的模板 (prompt)、预测文本中被遮掩掉 (masked) 的词语;
- 从文本中抽取答案:例如根据给定的问题从一段文本中抽取出对应的答案;
- 根据输入文本生成新的句子:例如文本翻译、自动摘要等。
Transformers库最基础的对象就是pipeline()函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的 pipelines 有:
- feature-extraction (获得文本的向量化表示)
- fill-mask (填充被遮盖的词、片段)
- ner(命名实体识别)
- question-answering (自动问答)
- sentiment-analysis (情感分析)
- summarization (自动摘要)
- text-generation (文本生成)
- translation (机器翻译)
- zero-shot-classification (零训练样本分类)
下面我们以常见的几个 NLP 任务为例,展示如何调用这些 pipeline 模型。
16.3.1 情感分析
借助情感分析 pipeline,我们只需要输入文本,就可以得到其情感标签(积极/消极)以及对应的概率:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I've been waiting for a HuggingFace course my whole life.")
print(result)
results = classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
print(results)pipeline 模型会自动完成以下三个步骤:
- 将文本预处理为模型可以理解的格式;
- 将预处理好的文本送入模型;
- 对模型的预测值进行后处理,输出人类可以理解的格式。
pipeline 会自动选择合适的预训练模型来完成任务。例如对于情感分析,默认就会选择微调好的英文情感模型 distilbert-base-uncased-finetuned-sst-2-english。
Transformers 库会在创建对象时下载并且缓存模型,只有在首次加载模型时才会下载,后续会直接调用缓存好的模型。
16.3.2 零训练样本分类
零训练样本分类 pipeline 允许我们在不提供任何标注数据的情况下自定义分类标签。
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
result = classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
print(result)可以看到,pipeline 自动选择了预训练好的 facebook/bart-large-mnli 模型来完成任务。
16.3.3 文本生成
我们首先根据任务需要构建一个模板 (prompt),然后将其送入到模型中来生成后续文本。注意,由于文本生成具有随机性,因此每次运行都会得到不同的结果。这种模板被称为前缀模板 (Prefix Prompt).
from transformers import pipeline
generator = pipeline("text-generation")
results = generator("In this course, we will teach you how to")
print(results)
results = generator(
"In this course, we will teach you how to",
num_return_sequences=2,
max_length=50
)
print(results)可以看到,pipeline 自动选择了预训练好的 gpt2 模型来完成任务。我们也可以指定要使用的模型。对于文本生成任务,我们可以在 Model Hub 页面左边选择 Text Generation tag 查询支持的模型。例如,我们在相同的 pipeline 中加载 distilgpt2 模型:
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
results = generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
print(results)还可以通过左边的语言 tag 选择其他语言的模型。例如加载专门用于生成中文古诗的 gpt2-chinese-poem 模型:
from transformers import pipeline
generator = pipeline("text-generation", model="uer/gpt2-chinese-poem")
results = generator(
"[CLS] 万 叠 春 山 积 雨 晴 ,",
max_length=40,
num_return_sequences=2,
)
print(results)16.3.4 遮盖词填充
给定一段部分词语被遮盖掉 (masked) 的文本,使用预训练模型来预测能够填充这些位置的词语.与前面介绍的文本生成类似,这个任务其实也是先构建模板然后运用模型来完善模板,称为填充模板 (Cloze Prompt)。
from transformers import pipeline
unmasker = pipeline("fill-mask")
results = unmasker("This course will teach you all about <mask> models.", top_k=2)
print(results)可以看到,pipeline 自动选择了预训练好的 distilroberta-base 模型来完成任务。
16.3.5 命名实体识别
命名实体识别 (NER) pipeline 负责从文本中抽取出指定类型的实体,例如人物、地点、组织等等。
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
results = ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
print(results)这里通过设置参数grouped_entities=True,使得 pipeline 自动合并属于同一个实体的多个子词 (token),例如这里将“Hugging”和“Face”合并为一个组织实体,实际上 Sylvain 也进行了子词合并,因为分词器会将 Sylvain 切分为 S、##yl 、##va 和 ##in 四个 token。
16.3.6 自动问答
自动问答 pipeline 可以根据给定的上下文回答问题,例如:
from transformers import pipeline
question_answerer = pipeline("question-answering")
answer = question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
print(answer)可以看到,pipeline自动选择了在 SQuAD 数据集上训练好的 distilbert-base 模型来完成任务。这里的自动问答 pipeline 实际上是一个抽取式问答模型,即从给定的上下文中抽取答案,而不是生成答案。 根据形式的不同,自动问答 (QA) 系统可以分为三种:
- 抽取式 QA (extractive QA):假设答案就包含在文档中,因此直接从文档中抽取答案;
- 多选 QA (multiple-choice QA):从多个给定的选项中选择答案,相当于做阅读理解题;
- 无约束 QA (free-form QA):直接生成答案文本,并且对答案文本格式没有任何限制。
16.3.7 自动摘要
自动摘要 pipeline 旨在将长文本压缩成短文本,并且还要尽可能保留原文的主要信息,例如:
from transformers import pipeline
summarizer = pipeline("summarization")
results = summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
print(results)可以看到,pipeline 自动选择了预训练好的 distilbart-cnn-12-6 模型来完成任务。与文本生成类似,我们也可以通过 max_length 或 min_length 参数来控制返回摘要的长度。
16.3.8 pipeline内部工作原理小窥
这些简单易用的 pipeline 模型实际上封装了许多操作,下面我们就来了解一下它们背后究竟做了啥。以第一个情感分析 pipeline 为例,我们运行下面的代码
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I've been waiting for a HuggingFace course my whole life.")
print(result)实际上它的背后经过了三个步骤:
- 预处理 (preprocessing),将原始文本转换为模型可以接受的输入格式;
- 将处理好的输入送入模型;
- 对模型的输出进行后处理 (postprocessing),将其转换为人类方便阅读的格式。
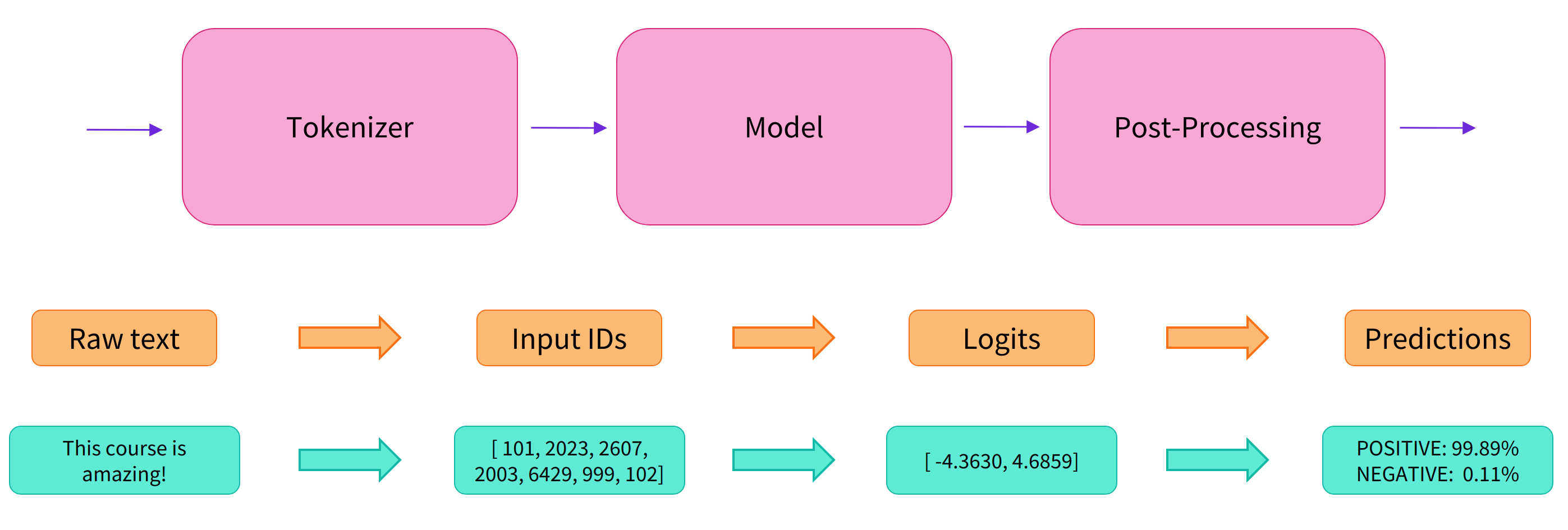
使用分词器进行预处理
因为神经网络模型无法直接处理文本,因此首先需要通过预处理环节将文本转换为模型可以理解的数字。具体地,我们会使用每个模型对应的分词器(tokenizer)来进行:
- 将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens;
- 根据模型的词表将每个 token 映射到对应的 token 编号(就是一个数字);
- 根据模型的需要,添加一些额外的输入。
我们对输入文本的预处理需要与模型自身预训练时的操作完全一致,只有这样,模型才可以正常地工作。注意,每个模型都有特定的预处理操作,如果对要使用的模型不熟悉,可以通过 Model Hub 查询。这里我们使用 AutoTokenizer 类和它的 from_pretrained() 函数,它可以自动根据模型 checkpoint 名称来获取对应的分词器。 情感分析pipeline的默认checkpoint是distilbert-base-uncased-finetuned-sst-2-english,下面我们手工下载并调用其分词器:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)将预处理好的输入送入模型
预训练模型的下载方式和分词器 (tokenizer) 类似,Transformers 包提供了一个 AutoModel 类和对应的 from_pretrained() 函数。下面我们手工下载这个 distilbert-base 模型:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)预训练模型的本体只包含基础的 Transformer 模块,对于给定的输入,它会输出一些神经元的值,称为 hidden states 或者特征 (features)。对于 NLP 模型来说,可以理解为是文本的高维语义表示。这些hidden states通常会被输入到其他的模型部分(称为head),以完成特定的任务,例如送入到分类头中完成文本分类任务。其实前面我们举例的所有 pipelines 都具有类似的模型结构,只是模型的最后一部分会使用不同的 head 以完成对应的任务。
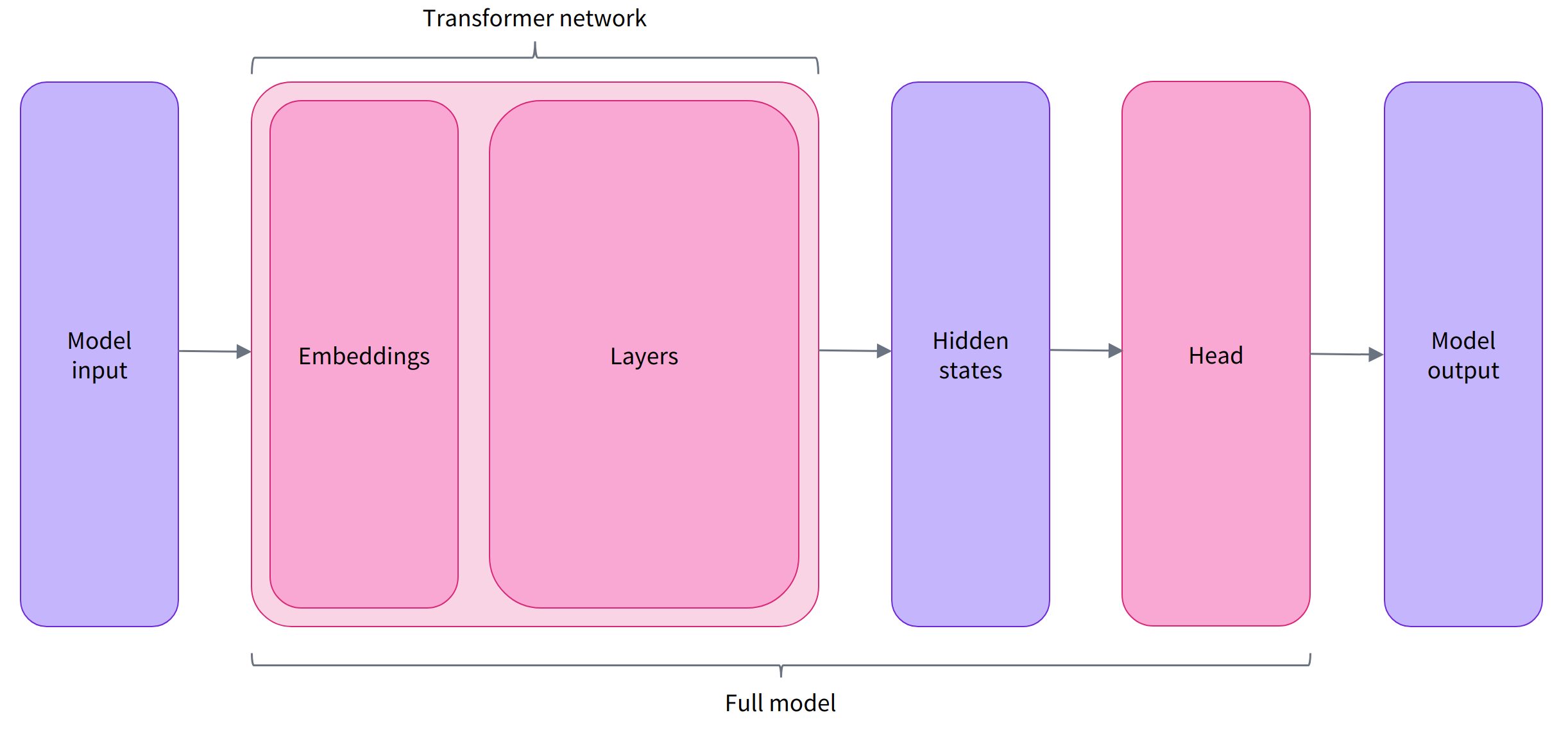
Transformers 库封装了很多不同的结构,常见的有:
- Model (返回 hidden states)
- ForCausalLM (用于条件语言模型)
- ForMaskedLM (用于遮盖语言模型)
- ForMultipleChoice (用于多选任务)
- ForQuestionAnswering (用于自动问答任务)
- ForSequenceClassification (用于文本分类任务)
- ForTokenClassification (用于 token 分类任务,例如 NER)
我们可以打印出这里使用的 distilbert-base 模型的输出维度:
from transformers import AutoTokenizer, AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModel.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
torch.Size([2, 16, 768])Transformers模型的输出格式类似namedtuple或字典,
- 可以像上面那样通过属性访问,
- 也可以通过键(outputs[“last_hidden_state”]),
- 甚至索引访问(outputs[0])。
对于情感分析任务,很明显我们最后需要使用的是一个文本分类 head。因此,实际上我们不会使用 AutoModel 类,而是使用 AutoModelForSequenceClassification:
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits.shape)
torch.Size([2, 2])对模型输出进行后处理
由于模型的输出只是一些数值,因此并不适合人类阅读。例如我们打印出上面例子的输出:
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits)它们并不是概率值,而是模型最后一层输出的 logits 值。要将他们转换为概率值,还需要让它们经过一个 SoftMax 层,例如:
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)最后,为了得到对应的标签,可以读取模型config中提供的id2label属性:
print(model.config.id2label)16.4 Sentence Transformers
model list: https://www.sbert.net/docs/pretrained_models.html
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
query_embedding = model.encode('How big is London')
passage_embedding = model.encode(['London has 9,787,426 inhabitants at the 2011 census',
'London is known for its finacial district'])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))16.5 Fine-Tuning Models
https://simpletransformers.ai/docs/installation/
支持的模型: https://simpletransformers.ai/docs/classification-specifics/#supported-model-types
from simpletransformers.classification import ClassificationModel, ClassificationArgs
import pandas as pd
import logginglogging.basicConfig(level=logging.INFO)
transformers_logger = logging.getLogger("transformers")
transformers_logger.setLevel(logging.WARNING)
# Preparing train data
train_data = [
["Aragorn was the heir of Isildur", 1.0],
["Frodo was the heir of Isildur", 0.0],
["Pippin is stronger than Merry", 0.3],
]
train_df = pd.DataFrame(train_data)
train_df.columns = ["text", "labels"]# Preparing eval data
eval_data = [
["Theoden was the king of Rohan", 1.0],
["Merry was the king of Rohan", 0.0],
["Aragorn is stronger than Boromir", 0.5],
]
eval_df = pd.DataFrame(eval_data)
eval_df.columns = ["text", "labels"]
# Enabling regression
# Setting optional model configuration
model_args = ClassificationArgs()
model_args.num_train_epochs = 1
model_args.regression = True
# Create a ClassificationModel
model = ClassificationModel(
"roberta",
"roberta-base",
num_labels=1,
args=model_args
)
# Train the model
model.train_model(train_df)# Evaluate the model
result, model_outputs, wrong_predictions = model.eval_model(eval_df)
# Make predictions with the model
predictions, raw_outputs = model.predict(["Sam was a Wizard"])16.6 FinBERT
https://github.com/yya518/FinBERT
FinBERT | 金融文本BERT模型,可情感分析、识别ESG和FLS类型
金融文本情绪可以调动管理者、信息中介和投资者的观点和意见, 因此分析金融文本情感(情绪)是有价值的。FinBERT-Sentiment 是一个 FinBERT 模型,它根据标准普尔 500 家公司的分析师报告中的 10,000 个手动注释的句子进行了Fine-tune(微调)。
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
#首次运行,因为会下载FinBERT模型,耗时会比较久
senti_finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-tone',num_labels=3)
senti_tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-tone')
senti_nlp = pipeline("text-classification", model=senti_finbert, tokenizer=senti_tokenizer)# 待分析的文本数据
senti_results = senti_nlp(['growth is strong and we have plenty of liquidity.',
'there is a shortage of capital, and we need extra financing.',
'formulation patents might protect Vasotec to a limited extent.'])
senti_results16.6.1 ESG 分类
ESG 分析可以帮助投资者确定企业的长期可持续性并识别相关风险。FinBERT-ESG 是一个 FinBERT 模型,根据来自公司 ESG 报告和年度报告的 2,000 个手动注释句子进行微调。
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
esg_finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-esg',
num_labels=4)
esg_tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-esg')
esg_nlp = pipeline("text-classification", model=esg_finbert, tokenizer=esg_tokenizer)esg_results = esg_nlp(['Managing and working to mitigate the impact our operations have on the environment is a core element of our business.',
'Rhonda has been volunteering for several years for a variety of charitable community programs.',
'Cabot\'s annual statements are audited annually by an independent registered public accounting firm.',
'As of December 31, 2012, the 2011 Term Loan had a principal balance of $492.5 million.'])
esg_results16.7 word embeddings
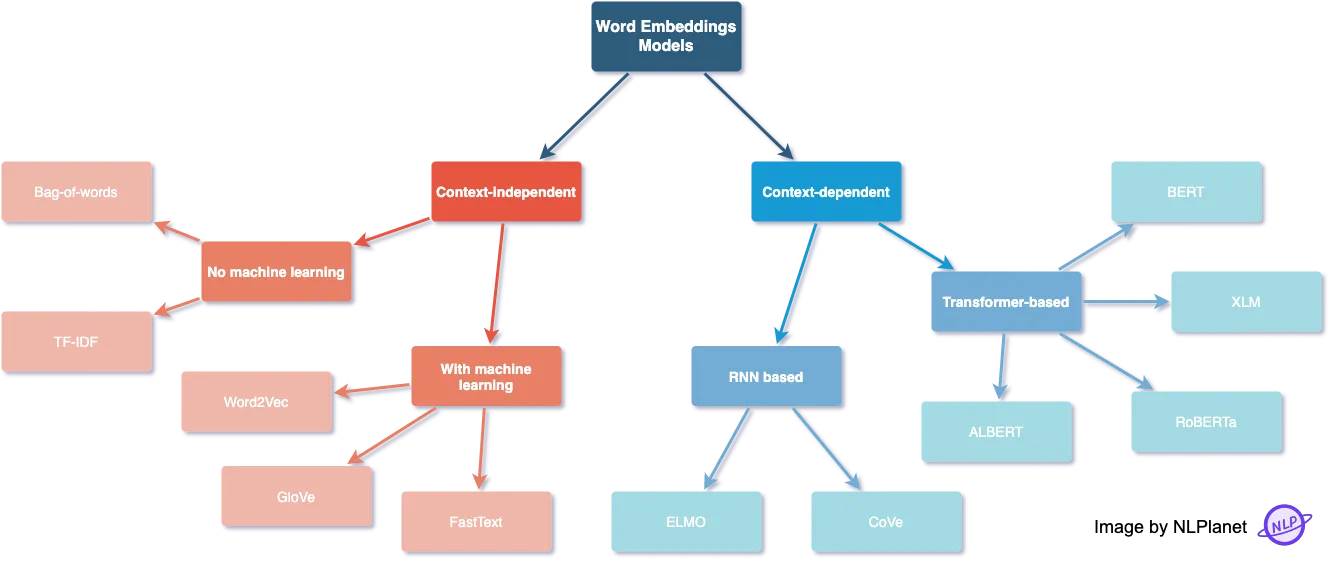
The role of word embeddings in deep models is important for providing input features to downstream tasks like sequence labeling and text classification. Several word embedding methods have been proposed in the past decade.
Context-independent
The learned representations are characterised by being unique and distinct for each word without considering the word’s context.
Context-independent without machine learning
- Bag-of-words: a text, such as a sentence or a document, is represented as the bag of its words, disregarding grammar and even word order but keeping multiplicity.
- TF-IDF: gets this importance score by getting the term’s frequency (TF) and multiplying it by the term inverse document frequency (IDF).
Context-independent with machine learning
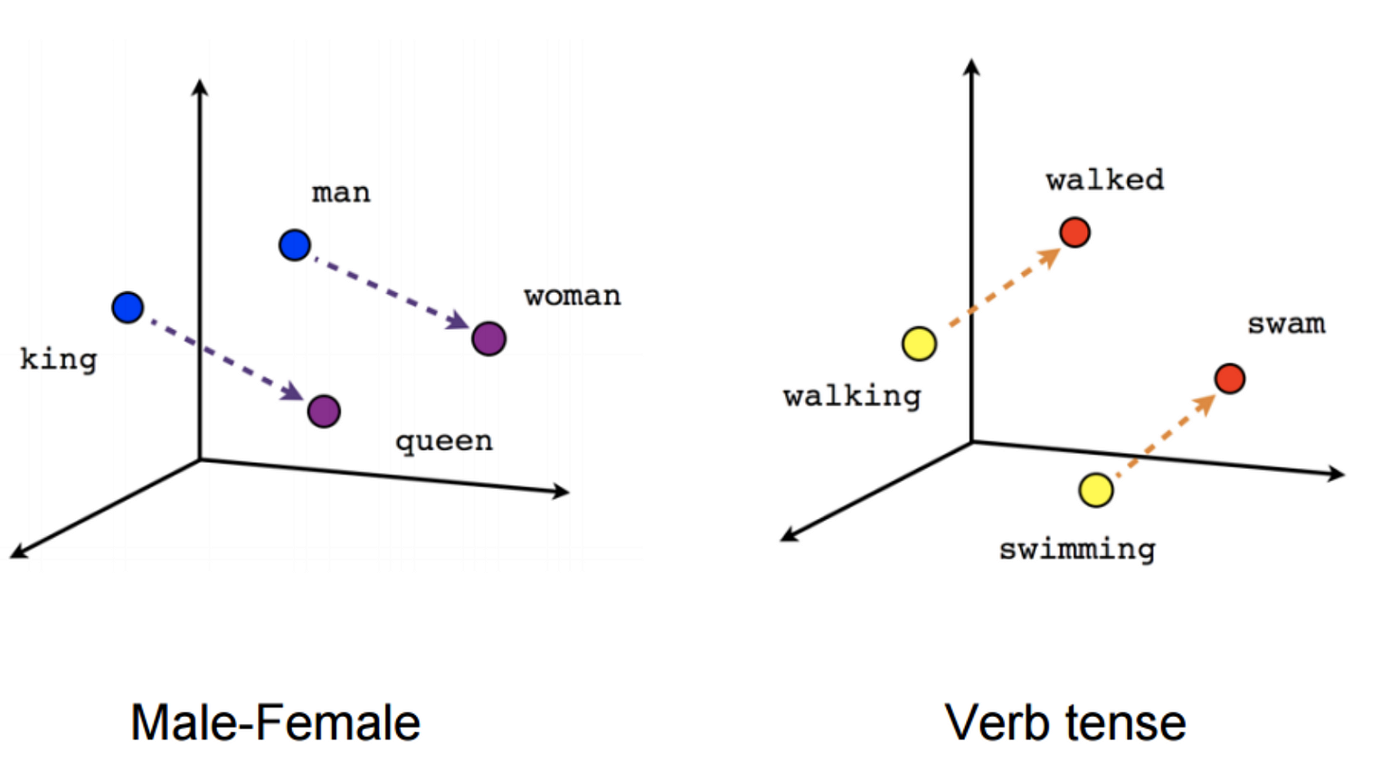
- Word2Vec: shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec can utilize either of two model architectures: continuous bag-of-words (CBOW) or continuous skip-gram. In the CBOW architecture, the model predicts the current word from a window of surrounding context words. In the continuous skip-gram architecture, the model uses the current word to predict the surrounding window of context words.
- GloVe (Global Vectors for Word Representation): Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
- FastText: unlike GloVe, it embeds words by treating each word as being composed of character n-grams instead of a word whole. This feature enables it not only to learn rare words but also out-of-vocabulary words.
Context-dependent
Unlike context-independent word embeddings, context-dependent methods learn different embeddings for the same word based on its context.
Context-dependent and RNN based
- ELMO (Embeddings from Language Model): learns contextualized word representations based on a neural language model with a character-based encoding layer and two BiLSTM layers.
- CoVe (Contextualized Word Vectors): uses a deep LSTM encoder from an attentional sequence-to-sequence model trained for machine translation to contextualize word vectors.
Context-dependent and transformer-based
- BERT (Bidirectional Encoder Representations from Transformers): transformer-based language representation model trained on a large cross-domain corpus. Applies a masked language model to predict words that are randomly masked in a sequence, and this is followed by a next-sentence-prediction task for learning the associations between sentences.
- XLM (Cross-lingual Language Model): it’s a transformer pretrained using next token prediction, a BERT-like masked language modeling objective, and a translation objective.
- RoBERTa (Robustly Optimized BERT Pretraining Approach): it builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with much larger mini-batches and learning rates.
- ALBERT (A Lite BERT for Self-supervised Learning of Language Representations): it presents parameter-reduction techniques to lower memory consumption and increase the training speed of BERT
Qiu, XiPeng, TianXiang Sun, YiGe Xu, YunFan Shao, Ning Dai, and XuanJing Huang. 2020. “Pre-Trained Models for Natural Language Processing: A Survey.” Science China Technological Sciences 63 (10): 1872–97. https://doi.org/10.1007/s11431-020-1647-3.