13 自然语言处理介绍
张奇、桂韬、黄萱菁. 2022. 自然语言处理导论. 上海. https://intro-nlp.github.io/
自然语言是指汉语、英语、法语等人们日常使用的语言,是自然而然的随着人类社会发展演变而来的语言,而不是人造的语言,它是人类学习生活的重要工具。 概括说来,自然语言是指人类社会约定俗成的,并且区别于人工语言(如计算机程序)的语言。
给我康康Duck不必美的家电,美的全面,美的彻底这个人谁都不认识
语言是人类与其他动物最重要的区别:
- 逻辑思维以语言的形式表达
- 知识以文字的形式记录和传播
13.1 自然语言处理概念
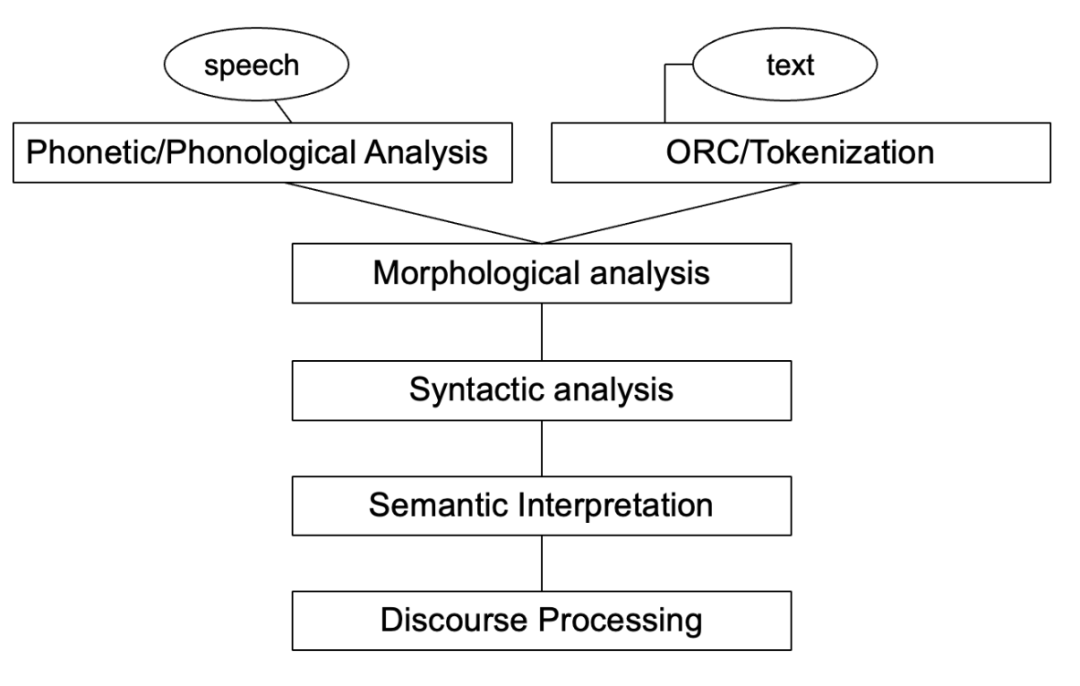
自然语言处理(Natural Language Processing,NLP)是计算机科学领域和人工智能领域的重要研究方向之一,旨在探索实现人与计算机之间用自然语言进行有效交流的理论与方法。它融合了语言学、计算机科学、机器学习、数学、认知心理学等多学科内容,涉及从字、词、短语到句 子、段落、篇章的多种语言单位,以及处理、理解、生成等不同层面的知识点
人工智能想要获取知识,就必须懂得理解人类使用的不太精确、可能有歧义、混乱的语言。
能够理解自然语言的意义 — 自然语言理解(Natural Language Understanding,NLU)
以自然语言文本来表达给定的意图、思想等 — 自然语言生成(Natural Language Generation,NLG)
13.1.1 NLP发展历史
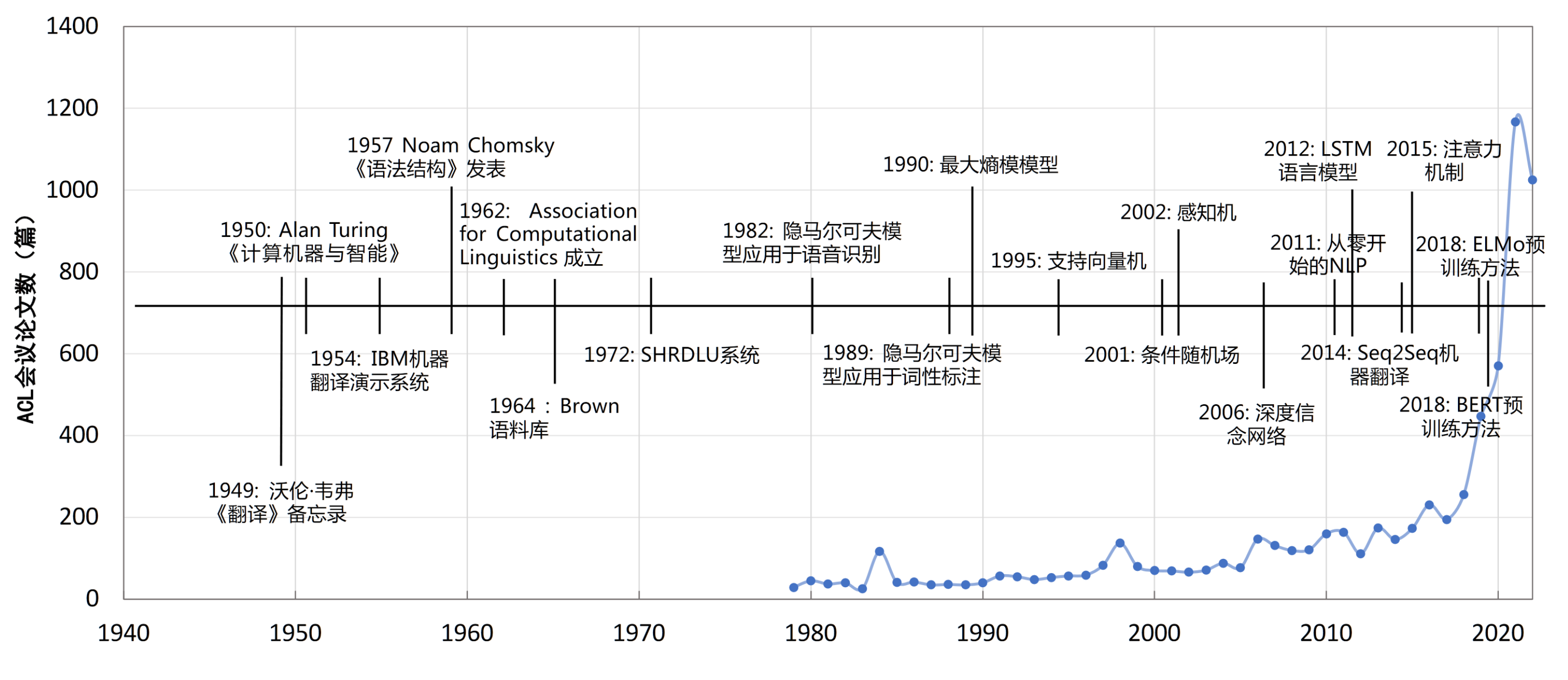
符号学派和随机学派
Noam Chomsky为代表的符号学派提出了形式语言理论,基于1957年发表的《Syntactic Structures》(句法结构)介绍了生成语法的概念,并提出了一种特定的生成语法称为转换语法。开启了使用数学方法研究语言的先河。
随机学派则是以1959年Bledsoe和Browning将贝叶斯方法(Bayesian method)应用于字符识别问题为代表。试图通过贝叶斯方法来解决自然语言处理中的问题。
20世纪70年代到80年代的理性主义时代
基于逻辑的范式、基于规则的范式和随机范式
1970年Colmerauer等人使用逻辑方法研制Q系统语言的先河
1972年SHRDLU系统使用规则范式模拟了一个玩具积木世界
80年代初隐马尔可夫模型等模型应用于词性标注、姓名检索等
20世纪90年代到21世纪初的经验主义时代
基于机器学习和数据驱动
1989年机器翻译任务中引入语料库
方法朴素贝叶斯、K近邻、支撑向量机、最大熵模型、神经网络、条件随机场、感知机等方法
2006年至今的深度学习时代
深度神经网络+向量表示
2006年基于深度信念网络(Deep Belief Networks, DBN)方法
2011年《Natural language processing (almost) from scratch》
2014 年 Seq2Seq(序列到序列)的模型在机器翻译任务上取得了非常好的效果,并且完全不依赖任何人工特征循环神经网络、长短时记忆网络、递归神经网络、卷积神经网络、图神经网络等
2018年至今大模型
2018年上下文相关的文本表示方法
ELMoBERT、GPT、XLNet、ERNIE等预训练微调范式
GPT3、Palm等超大规模语言模型
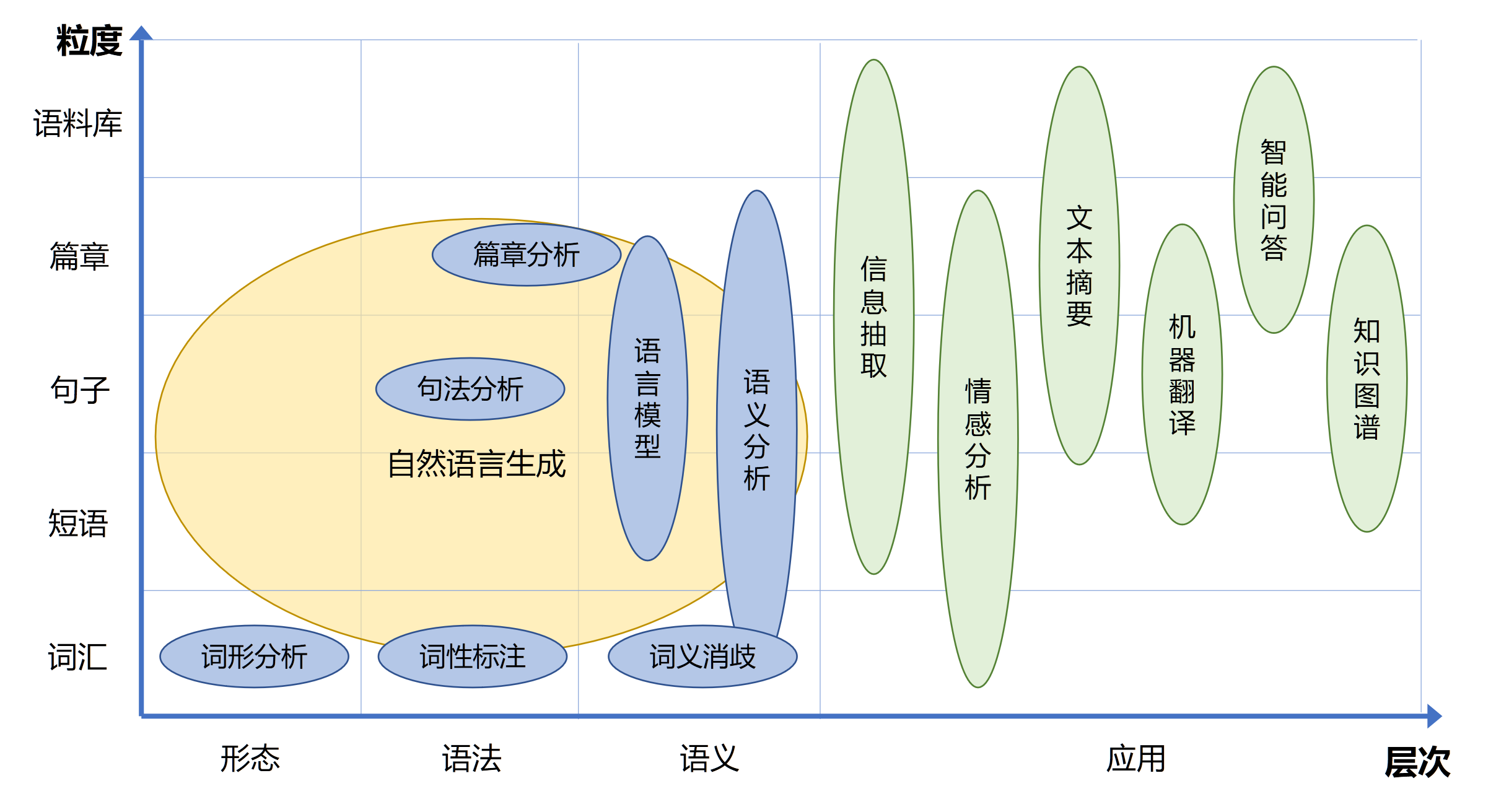
13.1.2 NLP研究内容
自然语言处理的研究内容十分庞杂
- 整体:基础算法研究和应用技术研究
- 语言单位角度:字、词、短语、句子、段落以及篇章等不同粒度
- 语言学研究角度:形态学、语法学、语义学、语用学等不同层面
- 机器学习方法层面:有监督、无监督、半监督、强化学习等
云NLP服务
- 阿里云自然语言处理: https://ai.aliyun.com/nlp
- 腾讯云NLP: https://cloud.tencent.com/product/nlp
- 百度智能云: https://cloud.baidu.com/product/nlp_basic
- 文心 ERNIE: https://wenxin.baidu.com/
13.1.3 自然语言处理的主要难点
语音歧义(Phonetic Ambiguity)主要体现在口语中,是由于语言中同音异义词(Homophone )、 爆破音不完全、重音位置不明确等原因造成的。汉字的同音异义现象则更加严重,在汉语中只有 413 个不同的音(节),如果结合声调的变化组合,也仅有 1277 个音(节),而汉字则多达数万个, 因此同音字非常多。
词语切分歧义(Word Segmentation Ambiguity)是由字符组成词语时的歧义现象。对于英语等印 欧语系的语言来说,绝大部分单词之间都由空格或标点分割。但是对于汉语、日语等语言来说,单 词之间通常没有分隔符。
词义歧义(Word Sense Ambiguity)是指词语具有相同形式但是不同意义。这种歧义在各种语言 中都广泛存在,通常越是常见的词语其词义数量就越多。
结构歧义(Structural Ambiguity)是由词组成词组或者句子时,由于其组成的词或词组间可能存 在不同的语法或语义关系而出现的(潜在)歧义现象。咬死了 | 猎人 | 的 | 狗
指代歧义, 在由多个句子组成的段落或篇章中,各种歧义依然存在,例如指代歧义和省略歧义。指代歧义 (Demonstrative Ambiguity)是指代词(如我,你,他等)和代词词组(如“那件事”,“这一点”等) 所指的事件可能存在歧义。 例如:猴子吃了香蕉,因为它 饿了。 猴子吃了香蕉,因为它 熟透了。
语用歧义(Pragmatic Ambiguity)是指由于上下文、说话人属性、场景等语用方面的原因造成 的歧义。一句话在不同的场合、由不同的人说、不同的语境,都可能产生不同的理解。女子致电男友:地铁站见。如果你到了我还没到,你就等着吧。 如果我到了你还没到, 你就等着吧!!
13.2 自然语言处理的基本范式
自然语言处理的发展经历了从理性主义到经验主义,再到深度学习三个大的历史阶段。在发展过程中也逐渐形成了一定的范式,主要包括:基于规则的方法、基于机器学习的方法以及基于深度学习的方法。
13.2.1 基于规则的方法
通过词汇、形式文法等制定的规则引入语言学知识,从而完成相应的自然语言处理任务。这类方法在自然语言处理早期受到了很大的关注,包括机器翻译在内的很多自然语言处理任务都采用此类方法。
规则引擎的目标是高效地解析这些人工定义的大量规则,针对输入数据根据规则库进行解 释执行,从而完成特定任务。这种方式可以使得语言学家不需要编写代码就可以完成规则库构建。
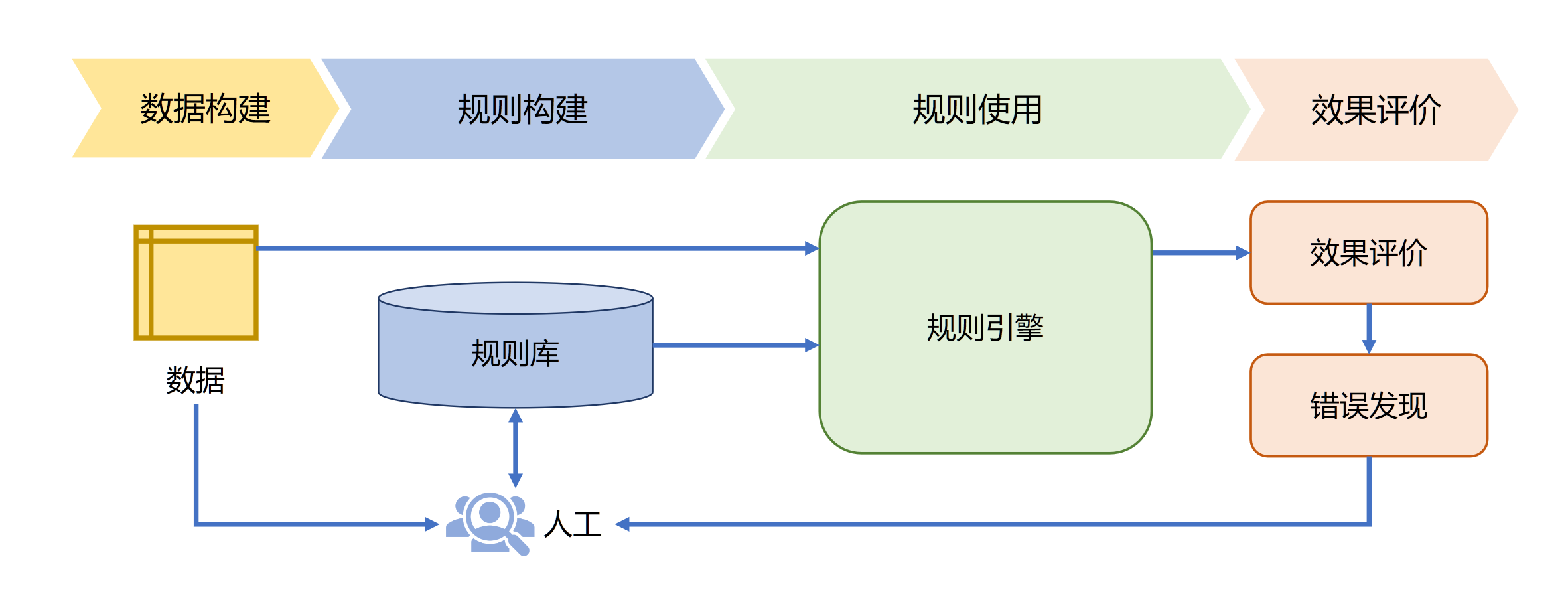
对于机器翻译任务可以构造如下规则库:
- IF 源语言主语 = 我 THEN 英语译文主语 =I
- IF 英语译文主语 =I THEN 英语译文 be 动词为 am/was
- IF 源语言 = 苹果 AND 没有修饰量词 THEN 英语译文 =apples
基于规则的方法从某种程度上可以说是在试图模拟人类完成某个任务时的思维过程
优点:直观、可解释、不依赖大规模数据。利用规则所表达出来的语言知识具有一定的可读性,不同的人之间可以相互理解。
缺点:覆盖率差、大规模规则构建代价大、难度高等
13.2.2 基于机器学习的方法
基于机器学习的自然语言处理算法绝大部分采用有监督分类算法,将自然语言处理任务转化为某种分类任务,在此基础上根据任务特性构建特征表示,并构建大规模的有标注语料,完成模型训练。
基于传统机器学习模型的范式,如 tf-idf 特征 + 朴素贝叶斯等机器算法
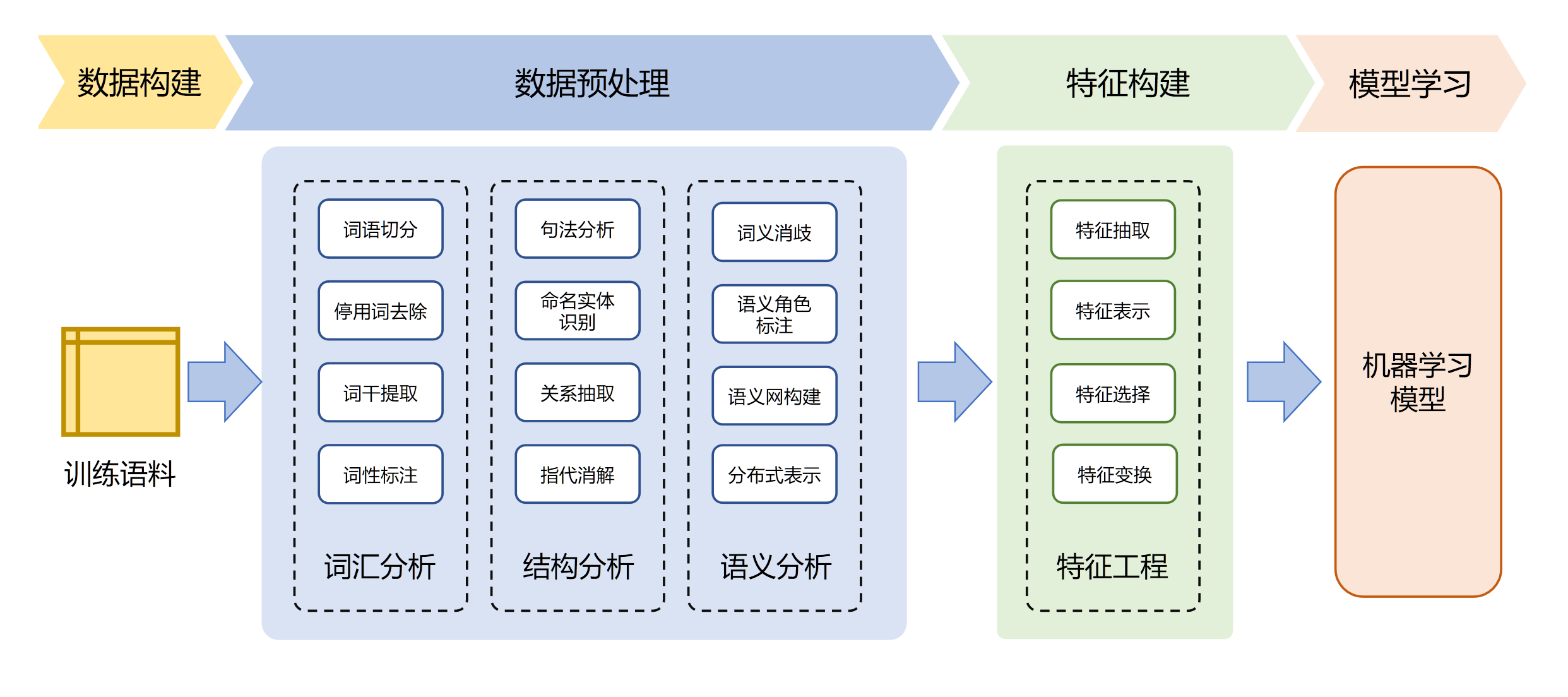
- 数据构建阶段主要工作是针对任务的要求构建训练语料,也称为语料库(Corpus)
- 数据预处理阶段主要工作是利用自然语言处理基础算法对原始输入,从词汇、句法、结构、语义等层面进行处理,为特征构建提供基础。
- 特征构建阶段主要工作是针对不同任务从原始输入、词性标注、句法分析、语义分析等结果和数据中提取对于机器学习模型有用的特征。
- 模型学习阶段主要工作是根据任务,选择合适的机器学习模型,确定学习准则,采用相应的优化算法,利用语料库训练模型参数。
以人工特征构建为核心,针对所需的信息利用自然语言处理基础算法对原始数据进行预处理,并需要选择合适的机器学习模型,确定学习准则,以及采用相应的优化算法
整个流程中需要人工参与和选择的环节非常多,从特征设计到模型,再到优化方法以及超参数,并且这些选择非常依赖经验,缺乏有效的理论支持
对于复杂的自然语言处理任务需要在数据预处理阶段引入很多不同的模块,这些模块之间需要单独优化,其目标并不一定与任务总体目标一致,多模块的级联会造成错误传播
13.2.3 基于深度学习的方法
深度学习(Deep Learning)方法通过构建有一定“深度”的模型,将特征学习和预测模型融合, 通过优化算法使得模型自动地学习出好的特征表示,并基于此进行结果预测。
在数据预处理方面也大幅度简化,仅包含非常少量的模块。甚至目前很多基于深度学习的自然语言处理算法可以完全省略数据预处理阶段,对于汉语直接使用汉字作为输入,不提前进行分词,对于英语也可以省略单词的规范化步骤。
基于深度学习模型的范式,如 word2vec 特征 + LSTM 等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;
基于预训练模型 + finetuning 的范式,如 BERT + finetuning 的 NLP 任务,相比于第二范式,模型准确度显著提高,但是模型也随之变得更大,但小数据集就可训练出好模型;
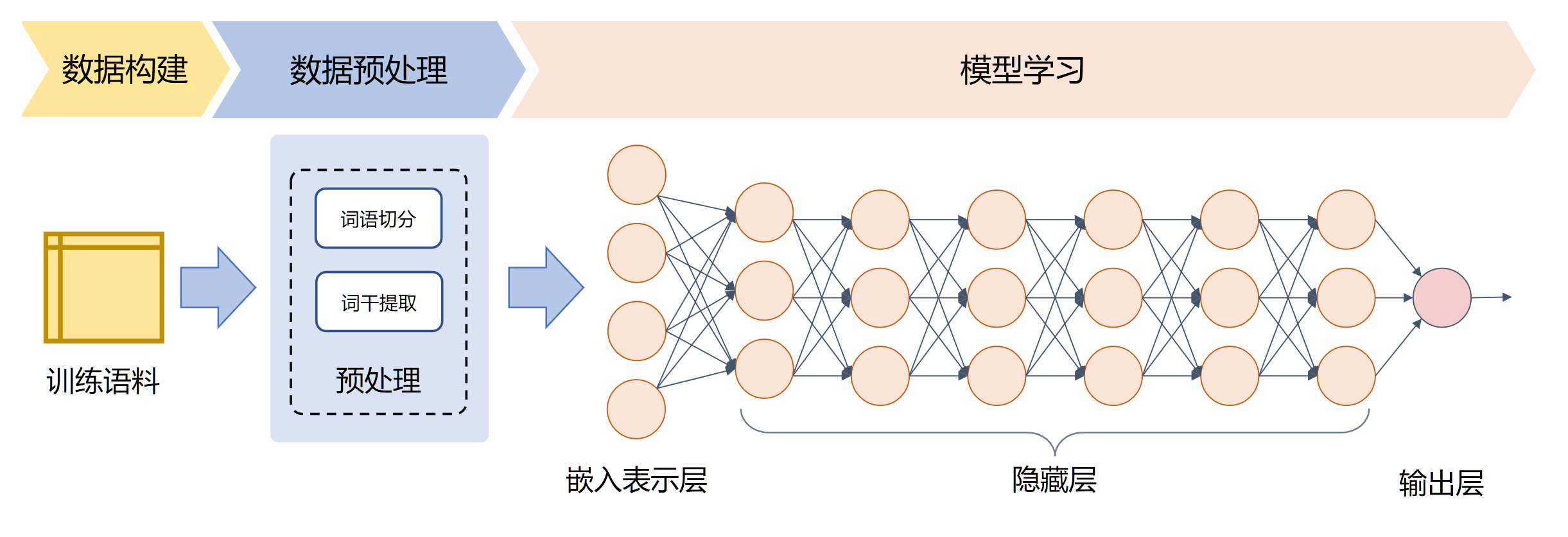
通过多层的特征转换,将原始数据转换为更抽象的表示。这些学习到的表示可以在一定程度上完全代替人工设计的特征,这个过程也叫做表示学习(Representation Learning)
自2018年ELMo模型提出之后,基于深度学习的自然语言处理范式又进一步演进为预训练微调范式。 首先利用自监督任务对模型进行预训练,通过海量的语料学习到更为通用的语言表示,然后根据下游任务对预训练网络进行调整。
预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。
预训练阶段一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的方式训练模型,期望模型能够获得语言相关的知识,比如句法,语法知识等等。经过超大规模语料的”洗礼”,预训练模型往往会是一个Super模型,一方面体现在它具备足够多的语言知识,一方面是因为它的参数规模很大。
微调阶段是利用预训练好的模型,去定制化地训练某些任务,使得预训练模型”更懂”这个任务。例如,利用预训练好的模型继续训练文本分类任务,将会获得比较好的一个分类结果,直观地想,预训练模型已经懂得了语言的知识,在这些知识基础上去学习文本分类任务将会事半功倍。利用预训练模型去微调的一些任务(例如前述文本分类)被称为下游任务(down-stream)。
以BERT为例,BERT是在海量数据中进行训练的,预训练阶段包含两个任务:MLM(Masked Language Model)和NSP (Next Sentence Prediction)。前者类似”完形填空”,在一句中扣出一个单词,然后利用这句话的其他单词去预测被扣出的这个单词;后者是给定两句话,判断这两句话在原文中是否是相邻的关系。
BERT预训练完成之后,后边可以接入多种类型的下游任务,例如文本分类,序列标注,阅读理解等等,通过在这些任务上进行微调,可以获得比较好的实验结果。
13.2.4 基于大模型的方法
大模型是大规模语言模型(Large Language Model)的简称。2018年开始以BERT、GPT为代表预训练语言模型相继推出,在各种自然语言处理任务上都得到了非常好的效果。
2020年Open AI发布的GPT-3模型的规模达到了1750亿,Google发布的PaLM模型的参数量达到了5400亿。
基于预训练模型 + Prompt + 预测的范式,如 BERT + Prompt 的范式相比于第三范式,模型训练所需的训练数据显著减少。
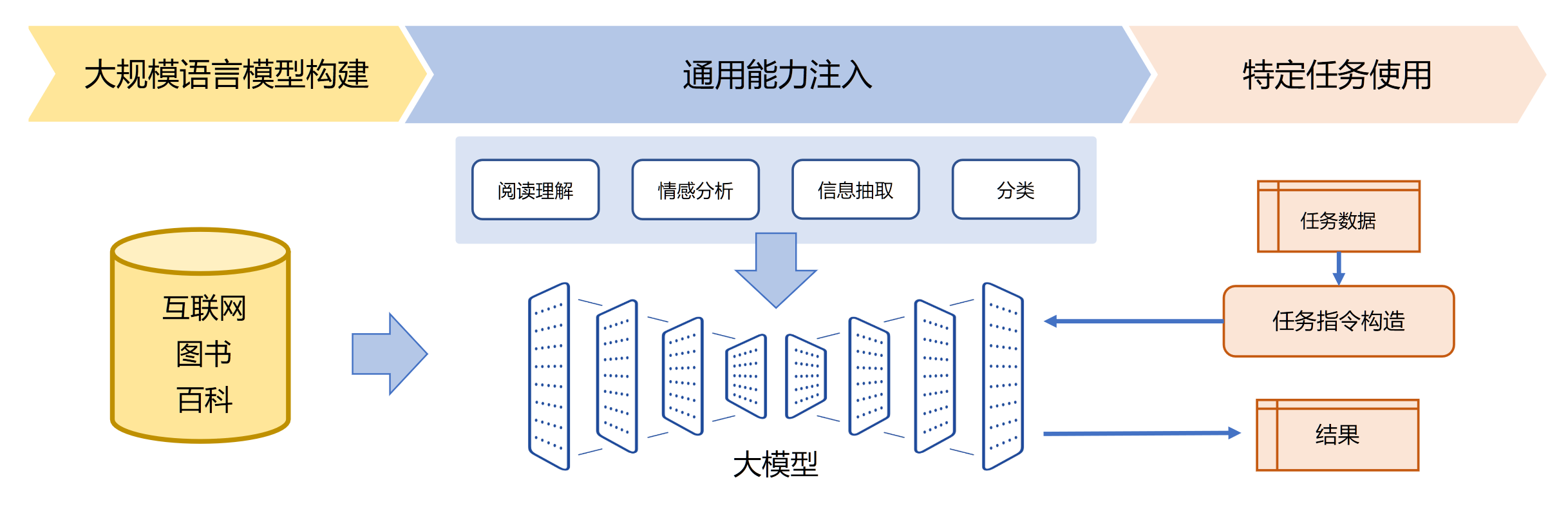
ChatGPT所展现出来的通用任务理解能力和未知任务泛化能力,使得未来自然语言处理的研究范式可能进一步发生变化
在大规模语言模型构建阶段,通过大量的文本内容,训练模型长文本的建模能力,使得模型具有语言生成能力,并使得模型获得隐式的世界知识在通用能力
注入阶段,利用包括阅读理解、情感分析、信息抽取等现有任务的标注数据,结合人工设计的指令词对模型进行多任务训练,从而使得模型具有很好的任务泛化能力
特定任务使用阶段则变得非常简单,由于模型具备了通用任务能力,只需要根据任务需求设计任务指令,将任务中所需处理的文本内容与指令结合,然后就可以利用大模型得到所需结果。
Prompt Learning介绍
在整个 NLP 领域,你会发现整个发展是朝着精度更高、少监督,甚至无监督的方向发展的,而Prompt Learning是目前学术界向这个方向进军最新也是最火的研究成果。
首先我们应该有的共识是:预训练模型中存在大量知识;预训练模型本身具有少样本学习能力。
GPT-3提出的In-Context Learning,也有效证明了在 Zero-shot、Few-shot 场景下,模型不需要任何参数,就能达到不错的效果,特别是近期很火的 GPT3.5 系列中的 ChatGPT。

Prompt Learning 的本质:
将所有下游任务统一成预训练任务;以特定的模板,将下游任务的数据转成自然语言形式,充分挖掘预训练模型本身的能力。
本质上就是设计一个比较契合上游预训练任务的模板,通过模板的设计就是挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务,关键包括 3 个步骤:
- 设计预训练语言模型的任务
- 设计输入模板样式(Prompt Engineering)
- 设计 label 样式及模型的输出映射到 label 的方式(Answer Engineering)
Prompt Learning 的形式:
以电影评论情感分类任务为例,模型需根据输入句子做二分类:
原始输入:特效非常酷炫,我很喜欢。
Prompt 输入:提示模板 1:特效非常酷炫,我很喜欢。这是一部 [MASK] 电影;提示模板 2:特效非常酷炫,我很喜欢。这部电影很 [MASK]
提示模板的作用就在于:将训练数据转成自然语言的形式,并在合适的位置 MASK,以激发预训练模型的能力。
通过构建提示学习样本,只需要少量数据的 Prompt Tuning,就可以实现很好的效果,具有较强的零样本/少样本学习能力。
Prompt Learning 的组成部分
- 提示模板:根据使用预训练模型,构建完形填空 or 基于前缀生成两种类型的模板
- 类别映射 / Verbalizer:根据经验选择合适的类别映射词
- 预训练语言模型
典型Prompt Learning方法总结
- 硬模板方法:人工设计/自动构建基于离散 token 的模板
- PET
- LM-BFF
- 软模板方法:不再追求模板的直观可解释性,而是直接优化 Prompt Token Embedding,是向量/可学习的参数
- P-tuning
- Prefix Tuning
13.3 其他课程资源
- NLP Course | For You: https://lena-voita.github.io/nlp_course.html
- NLP Course | 专属定制: https://mlnlp-world.github.io/NLP-Course-Chinese/index.html
- Applied Language Technology: https://applied-language-technology.mooc.fi/html/index.html
- Introduction to spaCy 3 https://spacy.pythonhumanities.com/intro.html
- 自然语言处理项目&工具库&资源大全