12 动态渲染页面爬取
https://cuiqingcai.com/202261.html
Ajax 的分析方法,利用 Ajax 接口我们可以非常方便地完成数据爬取。只要我们能找到 Ajax 接口的规律,就可以通过某些参数构造出对应的请求,数据自然就能轻松爬取到。但是在很多情况下,一些 Ajax 请求的接口通常会包含加密参数,如 token、sign 等,如:https://spa2.scrape.center/,它的 Ajax 接口是包含一个 token 参数的,如图所示。

此时解决方法通常有两种:一种就是深挖其中的逻辑,把其中 token 的构造逻辑完全找出来,再用 Python 复现,构造 Ajax 请求;另外一种方法就是直接通过模拟浏览器的方式来绕过这个过程,因为在浏览器里我们可以看到这个数据,如果能把看到的数据直接爬取下来,当然也就能获取对应的信息了。
12.1 Selenium
12.1.1 Selenium配置
pip install selenium
pip install webdriver-managerhttps://pypi.org/project/webdriver-manager
验证安装
12.1.2 Selenium使用
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))ChromeDriverManager().install()如果希望以后可以直接启动Chrome(),
在 Windows 下,建议直接将
chromedriver.exe文件复制到C:/Users/xxx/Ananconda3/文件夹。在 Linux、Mac 下,可以将
chromedriver文件 复制到/usr/local/bin/
这样就可以直接用 browser = webdriver.Chrome() 启动chrome,
如果不复制的话,每次启动都需要用:
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.baidu.com')
sleep(1)
browser.close()from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.taobao.com')
print(browser.page_source)12.1.3 声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。我们可以用如下方式初始化
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)By的类型
支持的方法 https://www.selenium.dev/selenium/docs/api/py/webdriver/selenium.webdriver.common.by.html
- CLASS_NAME = ‘class name’
- CSS_SELECTOR = ‘css selector’
- ID = ‘id’
- LINK_TEXT = ‘link text’
- NAME = ‘name’
- PARTIAL_LINK_TEXT = ‘partial link text’
- TAG_NAME = ‘tag name’
- XPATH = ‘xpath’
input_second = browser.find_element(By.CSS_SELECTOR, "#q")
input_third = browser.find_element(By.XPATH, '//*[@id="q"]')
print(input_first, input_second, input_third)12.1.4 多个节点
如果查找的目标在网页中只有一个,那么完全可以用 find_element 方法。但如果有多个节点,再用 find_element 方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用 find_elements 这样的方法。注意,在这个方法的名称中,element 多了一个 s,注意区分。
比如,要查找淘宝左侧导航条的所有条目,就可以这样来实现:
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.taobao.com')
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')
print(lis)12.1.5 节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.taobao.com')
input = browser.find_element(By.ID, 'q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element(By.TAG_NAME, 'button')
button.click()browser.save_screenshot("data/screen_taobao.png")通过上面的方法,我们完成了一些常见节点的操作,更多的操作可以参见官方文档的交互动作介绍 :http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
12.1.6 动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult') #
source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR, '#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明 ActionChains 对象并将其赋值为 actions 变量,然后通过调用 actions 变量的 drag_and_drop 方法,再调用 perform 方法执行动作,此时就完成了拖曳操作,如图所示。
更多的动作链操作可以参考官方文档的动作链介绍:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains。
12.1.7 执行 JavaScript
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script 方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')这里就利用 execute_script 方法将进度条下拉到最底部,然后弹出 alert 提示框。
所以说有了这个方法,基本上 API 没有提供的所有功能都可以用执行 JavaScript 的方式来实现了。
scroll down
You can use send_keys to simulate an END (or PAGE_DOWN) key press (which normally scroll the page):
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
html = browser.find_element(By.TAG_NAME, 'html')
html.send_keys(Keys.END)12.1.8 获取节点信息
前面说过,通过 page_source 属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery 等)来提取信息了。
不过,既然 Selenium 已经提供了选择节点的方法,返回的是 WebElement 类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
接下来,我们就来看看怎样获取节点信息吧。
12.1.9 获取属性
我们可以使用 get_attribute 方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
url = 'https://spa2.scrape.center/'
browser.get(url)
logo = browser.find_element(By.CSS_SELECTOR, '.logo-image')
print(logo)
print(logo.get_attribute('src'))运行之后,程序便会驱动浏览器打开该页面,然后获取 class 为 logo-image 的节点,最后打印出它的 src。
通过 get_attribute 方法,然后传入想要获取的属性名,就可以得到它的值了。
12.1.10 获取文本值
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于 pyquery 的 text 方法,示例如下:
input = browser.find_element(By.CSS_SELECTOR, '.logo-title')
print(input.text)12.1.11 获取 ID、位置、标签名和大小
另外,WebElement 节点还有一些其他属性,比如 id 属性可以获取节点 ID,location 属性可以获取该节点在页面中的相对位置,tag_name 属性可以获取标签名称,size 属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。示例如下:
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
url = 'https://spa2.scrape.center/'
browser.get(url)
input = browser.find_element(By.CSS_SELECTOR, '.logo-title')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)这里首先获得 class 为 logo-title 这个节点,然后调用其 id、location、tag_name、size 属性来获取对应的属性值。
12.1.12 切换 Frame
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame 方法来切换 Frame。示例如下:
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element(By.CSS_SELECTOR, '.logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element(By.CSS_SELECTOR, '.logo')
print(logo)
print(logo.text)这里还是以前面演示动作链操作的网页为实例,首先通过 switch_to.frame 方法切换到子 Frame 里面,然后尝试获取子 Frame 里的 logo 节点(这是找不到的),如果找不到的话,就会抛出 NoSuchElementException 异常,异常被捕捉之后,就会输出 NO LOGO。接下来,重新切换回父级 Frame,然后再次重新获取节点,发现此时可以成功获取了。
12.1.13 延时等待
在 Selenium 中,get 方法会在网页框架加载结束后结束执行,此时如果获取 page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待方式有两种:一种是隐式等待,一种是显式等待。
隐式等待
当使用隐式等待执行测试的时候,如果 Selenium 没有在 DOM 中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0。示例如下:
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.implicitly_wait(10)
browser.get('https://spa2.scrape.center/')
input = browser.find_element(By.CSS_SELECTOR, '.logo-image')
print(input)这里我们用 implicitly_wait 方法实现了隐式等待。
显式等待
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)这里首先引入 WebDriverWait 这个对象,指定最长等待时间,然后调用它的 until 方法,传入等待条件 expected_conditions。比如,这里传入了 presence_of_element_located 这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是 ID 为 q 的节点搜索框。
这样可以做到的效果就是,在 10 秒内如果 ID 为 q 的节点(即搜索框)成功加载出来,就返回该节点;如果超过 10 秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为 element_to_be_clickable,也就是可点击,所以查找按钮时查找 CSS 选择器为 .btn-search 的按钮,如果 10 秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过 10 秒还不可点击,也就是没有加载出来,就抛出异常。
运行代码,在网速较佳的情况下是可以成功加载出来的。
可以看到,控制台成功输出了两个节点,它们都是 WebElement 类型。
关于等待条件,其实还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。 更多等待条件的参数及用法介绍可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
12.1.14 前进后退
平常使用浏览器时,都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back 方法后退,使用 forward 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()这里我们连续访问 3 个页面,然后调用 back 方法回到第二个页面,接下来再调用 forward 方法又可以前进到第三个页面。
12.1.16 选项卡管理
在访问网页的时候,会开启一个个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')这里首先访问了百度,然后调用了 execute_script 方法,这里传入 window.open 这个 JavaScript 语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用 window_handles 属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用 switch_to.window 方法即可,其中参数是选项卡的代号。这里我们将第二个选项卡代号传入,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用 switch_to.window 方法,再执行其他操作即可。
12.1.17 异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用 try except 语句来捕获各种异常。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element(By.ID, 'hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
12.1.18 反屏蔽
现在很多网站都加上了对 Selenium 的检测,来防止一些爬虫的恶意爬取。即如果检测到有人在使用 Selenium 打开浏览器,那就直接屏蔽。
在大多数情况下,检测的基本原理是检测当前浏览器窗口下的 window.navigator 对象是否包含 webdriver 这个属性。因为在正常使用浏览器的情况下,这个属性是 undefined,然而一旦我们使用了 Selenium,Selenium 会给 window.navigator 设置 webdriver 属性。很多网站就通过 JavaScript 判断如果 webdriver 属性存在,那就直接屏蔽。
这边有一个典型的案例网站:https://antispider1.scrape.center/,这个网站就使用了上述原理实现了 WebDriver 的检测,如果使用 Selenium 直接爬取的话,那就会返回如图所示的页面。
这时候我们可能想到直接使用 JavaScript 语句把这个 webdriver 属性置空,比如通过调用 execute_script 方法来执行如下代码:
Object.defineProperty(navigator, "webdriver", { get: () => undefined });这行 JavaScript 语句的确可以把 webdriver 属性置空,但是 execute_script 调用这行 JavaScript 语句实际上是在页面加载完毕之后才执行的,执行太晚了,网站早在最初页面渲染之前就已经对 webdriver 属性进行了检测,所以用上述方法并不能达到效果。
在 Selenium 中,我们可以使用 CDP(即 Chrome Devtools-Protocol,Chrome 开发工具协议)来解决这个问题,通过它我们可以实现在每个页面刚加载的时候执行 JavaScript 代码,执行的 CDP 方法叫作 Page.addScriptToEvaluateOnNewDocument,然后传入上文的 JavaScript 代码即可,这样我们就可以在每次页面加载之前将 webdriver 属性置空了。另外,我们还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),
options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.center/')对于大多数情况,以上方法均可以实现 Selenium 反屏蔽。但对于一些特殊网站,如果它有更多的 WebDriver 特征检测,可能需要具体排查。
12.1.19 无头模式
我们可以观察到,上面的案例在运行的时候,总会弹出一个浏览器窗口,虽然有助于观察页面爬取状况,但在有时候窗口弹来弹去也会形成一些干扰。
Chrome 浏览器从 60 版本已经支持了无头模式,即 Headless。无头模式在运行的时候不会再弹出浏览器窗口,减少了干扰,而且它减少了一些资源的加载,如图片等,所以也在一定程度上节省了资源加载时间和网络带宽。
我们可以借助于 ChromeOptions 来开启 Chrome Headless 模式,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),
options=option)
browser.set_window_size(1366, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('data/preview.png')这里我们通过 ChromeOptions 的 add_argument 方法添加了一个参数 --headless,开启了无头模式。在无头模式下,我们最好设置一下窗口的大小,接着打开页面,最后我们调用 get_screenshot_as_file 方法输出了页面的截图。
12.1.20 eager mode
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = ChromeOptions()
options.page_load_strategy = 'eager'
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),
options=options)
driver.get("http://www.google.com")
driver.quit()12.2 pyppeeter
selenium 比如速度太慢、对版本配置要求严苛,经常要更新对应的驱动。还有些网页是可以检测到是否是使用了selenium 。并且selenium 所谓的保护机制不允许跨域 cookies 保存以及登录的时候必须先打开网页然后后加载 cookies 再刷新的方式很不友好。
另一款 web 自动化测试工具 Pyppeteer,虽然支持的浏览器比较单一,但在安装配置的便利性和运行效率方面都要远胜 selenium
Puppeteer 是 Google 基于 Node.js 开发的一个工具,主要是用来操纵 Chrome 浏览器的 API,通过 Javascript 代码来操纵 Chrome 浏览器的一些操作,用作网络爬虫完成数据爬取、Web 程序自动测试等任务。其 API 极其完善,功能非常强大
Pyppeteer 其实是 Puppeteer 的 Python 版本
安装命令如下:
pip install pyppeteer命令执行完毕之后即可完成安装。
安装完成之后可以运行如下命令进行一些初始化操作:
pyppeteer-install运行之后Pyppeteer 会下载一个 Chromium 浏览器并配置好环境变量。
Pyppeteer’s documentation: https://pyppeteer.github.io/pyppeteer/index.html
import nest_asyncio
nest_asyncio.apply()import asyncio
from pyppeteer import launch
async def main():
browser = await launch({'headless': False})
page = await browser.newPage()
await page.goto('http://www.example.com')
await page.screenshot({'path': 'data/example.png'})
await browser.close()
asyncio.run(main())12.2.1 快速上手
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch({'headless': False}) # 建立browser对象
page = await browser.newPage() # 新建page对象
await page.goto('https://spa2.scrape.center/')
await page.waitForSelector('.item .name') # 等待
doc = pq(await page.content()) # page html content
names = [item.text() for item in doc('.item .name').items()]
print('Names:', names)
asyncio.run(main())访问网站,等待某个项目出现,用pyquery筛选。不需要配置额外的内容,却方便的得到了Selenium的结果。
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://spa2.scrape.center/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='data/spa2_example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.run(main())设置了页面窗口的大小、保存了页面截图、执行JavaScript语句 并返回了对应的数据。其中,在screenshot方法里,通过path参数用于传入页面截图的保存路径, 另外还可以指定截图的保存格式type、清晰度quality,是否全屏fullPage和裁切clip等参数。
调用evaluate方法执行了一些JavaScript语句。这里给JavaScript传入了一个函数,使用return 方法返回了页面的宽、高、像素大小比率这三个值,最后得到的是一个JSON格式的对象。
12.2.2 load页面内容
import asyncio
from pyppeteer import launch
from bs4 import BeautifulSoup
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/')
## Get HTML
html = await page.content()
await browser.close()
return html
html_response = asyncio.run(main())
## Load HTML Response Into BeautifulSoup
soup = BeautifulSoup(html_response, "html.parser")
title = soup.find('h1').text
print('title', title)12.2.3 launch 方法
使用Pyppeteer的第一步便是启动浏览器。启动浏览器相当于点击桌面上的浏览器图标。 https://pyppeteer.github.io/pyppeteer/reference.html#launcher
headless(bool): Whether to run browser in headless mode. Defaults toTrueunlessappModeordevtoolsoptions isTrue.autoClose(bool): Automatically close browser process when script completed. Defaults toTrue.
async def main():
await launch(headless=False)12.2.4 调试模式
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(devtools=True)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.run(main())12.2.5 禁用提示条
browser = await launch(headless=False, args=['--disable-infobars'])12.2.6 防止检测
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.run(main())更改监测信息
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.run(main())12.2.7 使用代理
import asyncio
from pyppeteer import launch
async def main():
browser = await launch({'args': ['--proxy-server=127.0.0.1:7890'], 'headless': False })
page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/')
await browser.close()
asyncio.run(main())12.2.8 用户数据持久化
存储浏览器的数据,包括基本配置信息,还有cache、cookies等信息,下次启动可以直接使用这些信息。
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch(headless=False, userDataDir='./data/userdata',
args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.taobao.com')
asyncio.run(main())12.2.9 开启无痕浏览
import asyncio
from pyppeteer import launch
width, height = 1200, 768
async def main():
browser = await launch(headless=False)
context = await browser.createIncognitoBrowserContext()
page = await context.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)12.2.10 设置页面大小
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.run(main())12.2.11 页面处理
页面点击
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/')
## Click Button
link = await page.querySelector("h1")
await link.click()
await browser.close()滚动页面
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/scroll')
## Scroll To Bottom
await page.evaluate("""{window.scrollBy(0, document.body.scrollHeight);}""")
await browser.close()页面选择器
J方法就是querySelector返回第一个匹配到的节点 JJ方法就是querySelectorAll返回所有匹配到的节点
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
j_result1 = await page.J('.item .name')
j_result2 = await page.querySelector('.item .name')
jj_result1 = await page.JJ('.item .name')
jj_result2 = await page.querySelectorAll('.item .name')
print('J Result1:', j_result1)
print('J Result2:', j_result2)
print('JJ Result1:', jj_result1)
print('JJ Result2:', jj_result2)
await browser.close()选项卡
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
page = await browser.newPage()
await page.goto('https://www.bing.com')
pages = await browser.pages()
print('Pages:', pages)
page1 = pages[1]
await page1.bringToFront()
await asyncio.sleep(100)页面操作
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic1.scrape.cuiqingcai.com/')
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
# 后退
await page.goBack()
# 前进
await page.goForward()
# 刷新
await page.reload()
# 保存 PDF
await page.pdf()
# 截图
await page.screenshot()
# 设置页面 HTML
await page.setContent('<h2>Hello World</h2>')
# 设置 User-Agent
await page.setUserAgent('Python')
# 设置 Headers
await page.setExtraHTTPHeaders(headers={})
# 关闭
await page.close()
await browser.close()点击
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await page.click('.item .name', options={
'button': 'right',
'clickCount': 1, # 1 or 2
'delay': 3000, # 毫秒
})
await browser.close()输入文本
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.taobao.com')
# 后退
await page.type('#q', 'iPad')
# 关闭
await asyncio.sleep(10)
await browser.close()获取信息
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
print('HTML:', await page.content())
print('Cookies:', await page.cookies())
await browser.close()等待时间、条件
waitForXPath(xpath: str, options: dict = None, **kwargs)
waitForSelector(selector: str, options: dict = None, **kwargs)import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/')
await page.waitFor(5000)
## Next Steps
await browser.close()
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://quotes.toscrape.com/')
await page.waitForSelector('h1', {'visible': True})
## Next Steps
await browser.close()12.3 Playwright
Playwright 是微软在 2020 年初开源的新一代自动化测试工具,它的功能类似于 Selenium、Pyppeteer 等,都可以驱动浏览器进行各种自动化操作。它的功能也非常强大,对市面上的主流浏览器都提供了支持,API 功能简洁又强大。虽然诞生比较晚,但是现在发展得非常火热。
https://playwright.dev/python/docs/intro
12.3.1 Playwright 的特点
Playwright 支持当前所有主流浏览器,包括 Chrome 和 Edge(基于 Chromium)、Firefox、Safari(基于 WebKit) ,提供完善的自动化控制的 API。
Playwright 支持移动端页面测试,使用设备模拟技术可以使我们在移动 Web 浏览器中测试响应式 Web 应用程序。
Playwright 支持所有浏览器的 Headless 模式和非 Headless 模式的测试。
Playwright 的安装和配置非常简单,安装过程中会自动安装对应的浏览器和驱动,不需要额外配置 WebDriver 等。
Playwright 提供了自动等待相关的 API,当页面加载的时候会自动等待对应的节点加载,大大简化了 API 编写复杂度。
12.3.2 安装
要安装 Playwright,可以直接使用 pip 命令如下
pip install playwright安装完成之后需要进行一些初始化操作:
playwright install这时候 Playwrigth 会安装 Chromium, Firefox and WebKit 浏览器并配置一些驱动,我们不必关心中间配置的过程,Playwright 会为我们配置好。 https://setup.scrape.center/playwright
12.3.3 基本使用
Playwright 支持两种编写模式,一种是类似 Pyppetter 一样的异步模式,另一种是像 Selenium 一样的同步模式,我们可以根据实际需要选择使用不同的模式。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
page.screenshot(path=f'data/screenshot-{browser_type.name}.png')
print(page.title())
browser.close()首先我们导入了 sync_playwright 方法,然后直接调用了这个方法,该方法返回的是一个 PlaywrightContextManager 对象,可以理解是一个浏览器上下文管理器,我们将其赋值为变量 p。
接着我们调用了 PlaywrightContextManager 对象的 chromium、firefox、webkit 属性依次创建了一个 Chromium、Firefox 以及 Webkit 浏览器实例,接着用一个 for 循环依次执行了它们的 launch 方法,同时设置了 headless 参数为 False。
launch 方法返回的是一个 Browser 对象,我们将其赋值为 browser 变量。然后调用 browser 的 new_page 方法,相当于新建了一个选项卡,返回的是一个 Page 对象,将其赋值为 page,这整个过程其实和 Pyppeteer 非常类似。接着我们就可以调用 page 的一系列 API 来进行各种自动化操作了,比如调用 goto,就是加载某个页面,这里我们访问的是百度的首页。接着我们调用了 page 的 screenshot 方法,参数传一个文件名称,这样截图就会自动保存为该图片名称,这里名称中我们加入了 browser_type 的 name 属性,代表浏览器的类型,结果分别就是 chromium, firefox, webkit。
运行一下,这时候我们可以看到有三个浏览器依次启动并加载了百度这个页面,分别是 Chromium、Firefox 和 Webkit 三个浏览器,页面加载完成之后,生成截图、控制台打印结果就退出了。
当然除了同步模式,Playwright 还提供异步的 API,如果我们项目里面使用了 asyncio,那就应该使用异步模式,写法如下:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = await browser_type.launch()
page = await browser.new_page()
await page.goto('https://www.baidu.com')
await page.screenshot(path=f'data/screenshot-{browser_type.name}.png')
print(await page.title())
await browser.close()
asyncio.run(main())可以看到整个写法和同步模式基本类似,导入的时候使用的是 async_playwright 方法,而不再是 sync_playwright 方法。写法上添加了 async/await 关键字的使用,最后的运行效果是一样的。
另外我们注意到,这例子中使用了 with as 语句,with 用于上下文对象的管理,它可以返回一个上下文管理器,也就对应一个 PlaywrightContextManager 对象,无论运行期间是否抛出异常,它能够帮助我们自动分配并且释放 Playwright 的资源。
12.3.4 代码生成
Playwright 还有一个强大的功能,那就是可以录制我们在浏览器中的操作并将代码自动生成出来,有了这个功能,我们甚至都不用写任何一行代码,这个功能可以通过 playwright 命令行调用 codegen 来实现,我们先来看看 codegen 命令都有什么参数,输入如下命令:
playwright codegen --help可以看到这里有几个选项,比如 -o 代表输出的代码文件的名称;-target 代表使用的语言,默认是 python,即会生成同步模式的操作代码,如果传入 python-async 就会生成异步模式的代码;-b 代表的是使用的浏览器,默认是 Chromium,其他还有很多设置,比如 -device 可以模拟使用手机浏览器,比如 iPhone 11,-lang 代表设置浏览器的语言,-timeout 可以设置页面加载超时时间。
好,了解了这些用法,那我们就来尝试启动一个 Firefox 浏览器,然后将操作结果输出到 script.py 文件,命令如下:
playwright codegen -o script.py -b chromium https://www.baidu.com这时候就弹出了一个 chrommium 浏览器,同时右侧会输出一个脚本窗口,实时显示当前操作对应的代码。
可以看到这里生成的代码和我们之前写的示例代码几乎差不多,而且也是完全可以运行的,运行之后就可以看到它又可以复现我们刚才所做的操作了。
所以,有了这个功能,我们甚至都不用编写任何代码,只通过简单的可视化点击就能把代码生成出来,可谓是非常方便了!
另外这里有一个值得注意的点,仔细观察下生成的代码,和前面的例子不同的是,这里 new_page 方法并不是直接通过 browser 调用的,而是通过 context 变量调用的,这个 context 又是由 browser 通过调用 new_context 方法生成的。
其实这个 context 变量对应的是一个 BrowserContext 对象,BrowserContext 是一个类似隐身模式的独立上下文环境,其运行资源是单独隔离的,在做一些自动化测试过程中,每个测试用例我们都可以单独创建一个 BrowserContext 对象,这样可以保证每个测试用例之间互不干扰,具体的 API 可以参考 https://playwright.dev/python/docs/api/class-browsercontext
12.3.5 移动端浏览器支持
Playwright 另外一个特色功能就是可以支持移动端浏览器的模拟,比如模拟打开 iPhone 12 Pro Max 上的 Safari 浏览器,然后手动设置定位,并打开百度地图并截图。首先我们可以选定一个经纬度,比如故宫的经纬度是 39.913904, 116.39014,我们可以通过 geolocation 参数传递给 Webkit 浏览器并初始化。
示例代码如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
iphone_12_pro_max = p.devices['iPhone 12 Pro Max']
browser = p.webkit.launch(headless=False)
context = browser.new_context(
**iphone_12_pro_max,
locale='zh-CN',
geolocation={'longitude': 116.39014, 'latitude': 39.913904},
permissions=['geolocation']
)
page = context.new_page()
page.goto('https://amap.com')
page.wait_for_load_state(state='networkidle')
page.screenshot(path='location-iphone.png')
browser.close()这里我们先用 PlaywrightContextManager 对象的 devices 属性指定了一台移动设备,这里传入的是手机的型号,比如 iPhone 12 Pro Max,当然也可以传其他名称,比如 iPhone 8,Pixel 2 等。
前面我们已经了解了 BrowserContext 对象,BrowserContext 对象也可以用来模拟移动端浏览器,初始化一些移动设备信息、语言、权限、位置等信息,这里我们就用它来创建了一个移动端 BrowserContext 对象,通过 geolocation 参数传入了经纬度信息,通过 permissions 参数传入了赋予的权限信息,最后将得到的 BrowserContext 对象赋值为 context 变量。
接着我们就可以用 BrowserContext 对象来新建一个页面,还是调用 new_page 方法创建一个新的选项卡,然后跳转到高德地图,并调用了 wait_for_load_state 方法等待页面某个状态完成,这里我们传入的 state 是 networkidle,也就是网络空闲状态。因为在页面初始化和加载过程中,肯定是伴随有网络请求的,所以加载过程中肯定不算 networkidle 状态,所以这里我们传入 networkidle 就可以标识当前页面和数据加载完成的状态。加载完成之后,我们再调用 screenshot 方法获取当前页面截图,最后关闭浏览器。
12.3.6 选择器
传入的这个字符串,我们可以称之为 Element Selector,它不仅仅支持 CSS 选择器、XPath,Playwright 还扩展了一些方便好用的规则,比如直接根据文本内容筛选,根据节点层级结构筛选等等。
文本选择
文本选择支持直接使用 text= 这样的语法进行筛选,示例如下:
page.click("text=Log in")这就代表选择文本是 Log in 的节点,并点击。
CSS 选择器
CSS 选择器之前也介绍过了,比如根据 id 或者 class 筛选:
page.click("button")
page.click("#nav-bar .contact-us-item")根据特定的节点属性筛选:
page.click("[data-test=login-button]")
page.click("[aria-label='Sign in']")CSS 选择器 + 文本
我们还可以使用 CSS 选择器结合文本值进行海选,比较常用的就是 has-text 和 text,前者代表包含指定的字符串,后者代表字符串完全匹配,示例如下:
page.click("article:has-text('Playwright')")
page.click("#nav-bar :text('Contact us')")第一个就是选择文本中包含 Playwright 的 article 节点,第二个就是选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点。
CSS 选择器 + 节点关系
还可以结合节点关系来筛选节点,比如使用 has 来指定另外一个选择器,示例如下:
page.click(".item-description:has(.item-promo-banner)")比如这里选择的就是选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点。
另外还有一些相对位置关系,比如 right-of 可以指定位于某个节点右侧的节点,示例如下:
page.click("input:right-of(:text('Username'))")这里选择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧。
XPath
当然 XPath 也是支持的,不过 xpath 这个关键字需要我们自行制定,示例如下:
page.click("xpath=//button")这里需要在开头指定 xpath= 字符串,代表后面是一个 XPath 表达式。
关于更多选择器的用法和最佳实践,可以参考官方文档: https://playwright.dev/python/docs/selectors
12.3.7 常用操作方法
上面我们了解了浏览器的一些初始化设置和基本的操作实例,下面我们再对一些常用的操作 API 进行说明。
常见的一些 API 如点击 click,输入 fill 等操作,这些方法都是属于 Page 对象的,所以所有的方法都从 Page 对象的 API 文档查找就好了,文档地址: https://playwright.dev/python/docs/api/class-page
下面介绍几个常见的 API 用法。
事件监听
Page 对象提供了一个 on 方法,它可以用来监听页面中发生的各个事件,比如 close、console、load、request、response 等等。
比如这里我们可以监听 response 事件,response 事件可以在每次网络请求得到响应的时候触发,我们可以设置对应的回调方法获取到对应 Response 的全部信息,示例如下:
from playwright.sync_api import sync_playwright
def on_response(response):
print(f'Statue {response.status}: {response.url}')
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()这里我们在创建 Page 对象之后,就开始监听 response 事件,同时将回调方法设置为 on_response,on_response 对象接收一个参数,然后把 Response 的状态码和链接都输出出来了。
可以看到,这里的输出结果其实正好对应浏览器 Network 面板中所有的请求和响应内容,和下图是一一对应的:
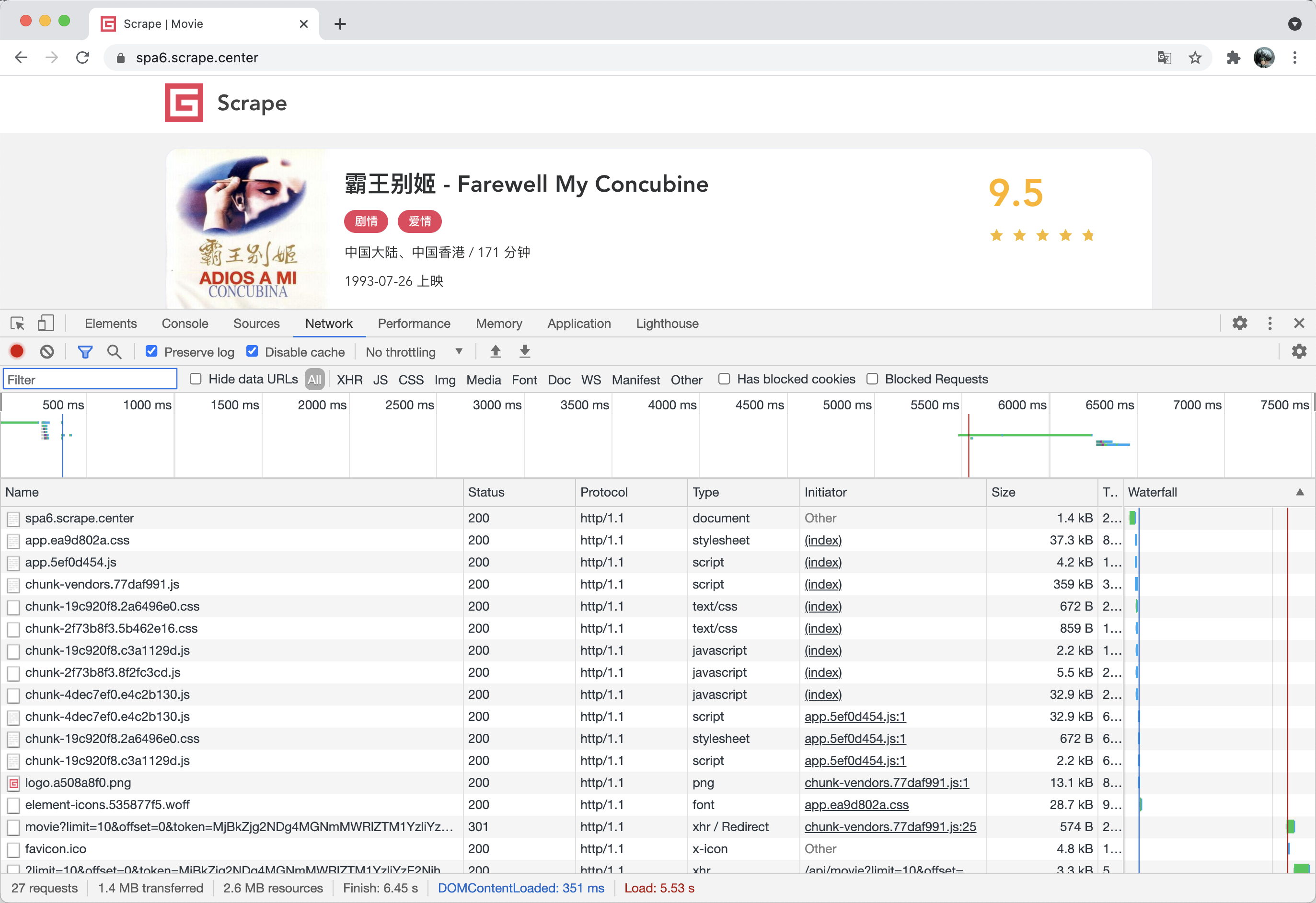
这个网站我们之前分析过,其真实的数据都是 Ajax 加载的,同时 Ajax 请求中还带有加密参数,不好轻易获取。
但有了这个方法,这里如果我们想要截获 Ajax 请求,岂不是就非常容易了?
改写一下判定条件,输出对应的 JSON 结果,改写如下:
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()我们直接通过这个方法拦截了 Ajax 请求,直接把响应结果拿到了,即使这个 Ajax 请求有加密参数,我们也不用关心,因为我们直接截获了 Ajax 最后响应的结果。
获取页面源码
要获取页面的 HTML 代码其实很简单,我们直接通过 content 方法获取即可,用法如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
html = page.content()
print(html)
browser.close()运行结果就是页面的 HTML 代码。获取了 HTML 代码之后,我们通过一些解析工具就可以提取想要的信息了。
页面点击
刚才我们通过示例也了解了页面点击的方法,那就是 click,这里详细说一下其使用方法。
page.click(selector, **kwargs)这里可以看到必传的参数是 selector,其他的参数都是可选的。第一个 selector 就代表选择器,可以用来匹配想要点击的节点,如果传入的选择器匹配了多个节点,那么只会用第一个节点。
这个方法的内部执行逻辑如下:
- 根据 selector 找到匹配的节点,如果没有找到,那就一直等待直到超时,超时时间可以由额外的 timeout 参数设置,默认是 30 秒。
- 等待对该节点的可操作性检查的结果,比如说如果某个按钮设置了不可点击,那它会等待该按钮变成了可点击的时候才去点击,除非通过 force 参数设置跳过可操作性检查步骤强制点击。
- 如果需要的话,就滚动下页面,将需要被点击的节点呈现出来。
- 调用 page 对象的 mouse 方法,点击节点中心的位置,如果指定了 position 参数,那就点击指定的位置。
click 方法的一些比较重要的参数如下:
- click_count:点击次数,默认为 1。
- timeout:等待要点击的节点的超时时间,默认是 30 秒。
- position:需要传入一个字典,带有 x 和 y 属性,代表点击位置相对节点左上角的偏移位置。
- force:即使不可点击,那也强制点击。默认是 False。
具体的 API 设置参数可以参考官方文档:https://playwright.dev/python/docs/api/class-page/#pageclickselector-kwargs。
文本输入
文本输入对应的方法是 fill,API 定义如下:
page.fill(selector, value, **kwargs)这个方法有两个必传参数,第一个参数也是 selector,第二个参数是 value,代表输入的内容,另外还可以通过 timeout 参数指定对应节点的最长等待时间。
获取节点属性
除了对节点进行操作,我们还可以获取节点的属性,方法就是 get_attribute,API 定义如下:
page.get_attribute(selector, name, **kwargs)这个方法有两个必传参数,第一个参数也是 selector,第二个参数是 name,代表要获取的属性名称,另外还可以通过 timeout 参数指定对应节点的最长等待时间。
示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
href = page.get_attribute('a.name', 'href')
print(href)
browser.close()获取多个节点
获取所有节点可以使用 query_selector_all 方法,它可以返回节点列表,通过遍历获取到单个节点之后,我们可以接着调用单个节点的方法来进行一些操作和属性获取,示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
elements = page.query_selector_all('a.name')
for element in elements:
print(element.get_attribute('href'))
print(element.text_content())
browser.close()这里我们通过 query_selector_all 方法获取了所有匹配到的节点,每个节点对应的是一个 ElementHandle 对象,然后 ElementHandle 对象也有 get_attribute 方法来获取节点属性,另外还可以通过 text_content 方法获取节点文本。
获取单个节点
获取单个节点也有特定的方法,就是 query_selector,如果传入的选择器匹配到多个节点,那它只会返回第一个节点,示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
element = page.query_selector('a.name')
print(element.get_attribute('href'))
print(element.text_content())
browser.close()12.3.8 网络劫持
最后再介绍一个实用的方法 route,利用 route 方法,我们可以实现一些网络劫持和修改操作,比如修改 request 的属性,修改 response 响应结果等。
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/")
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()这里我们调用了 route 方法,第一个参数通过正则表达式传入了匹配的 URL 路径,这里代表的是任何包含 .png 或 .jpg 的链接,遇到这样的请求,会回调 cancel_request 方法处理,cancel_request 方法可以接收两个参数,一个是 route,代表一个 CallableRoute 对象,另外一个是 request,代表 Request 对象。这里我们直接调用了 route 的 abort 方法,取消了这次请求,所以最终导致的结果就是图片的加载全部取消了。
这个设置有什么用呢?其实是有用的,因为图片资源都是二进制文件,而我们在做爬取过程中可能并不想关心其具体的二进制文件的内容,可能只关心图片的 URL 是什么,所以在浏览器中是否把图片加载出来就不重要了。所以如此设置之后,我们可以提高整个页面的加载速度,提高爬取效率。
另外,利用这个功能,我们还可以将一些响应内容进行修改,比如直接修改 Response 的结果为自定义的文本文件内容。
首先这里定义一个 HTML 文本文件,命名为 custom_response.html,内容如下:
<!DOCTYPE html>
<html>
<head>
<title>Hack Response</title>
</head>
<body>
<h1>Hack Response</h1>
</body>
</html>代码编写如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def modify_response(route, request):
route.fulfill(path="./data/custom_response.html")
page.route('/', modify_response)
page.goto("https://spa6.scrape.center/")这里我们使用 route 的 fulfill 方法指定了一个本地文件,就是刚才我们定义的 HTML 文件。
可以看到,Response 的运行结果就被我们修改了,URL 还是不变的,但是结果已经成了我们修改的 HTML 代码。
12.4 可能问题
1. selenium找不到系统的chrome浏览器
# Error: WebDriverException
# (No symbol)
# [0x078C63B]BaseThreadInitThunk [0x767FOOF9+25]
# RtlGetAppContainerNamedObjectPath [0x77B67BBE+286]
# RtlGetAppContainerNamedObjectPath[0x77B67B8E+238]from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.binary_location = r"C:/Program Files/Google/Chrome/Application/chrome.exe"
# options.binary_location = r'C:/Users/xxx/AppData/Local/Google/Chrome/Application/chrome.exe'
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),
options=options)2. logging error 的问题
ERROR:device_event_log_impl.cc(222)] [12:57:51.699] USB: usb_device_handle_win.cc:1046 Failed to read descriptor from node connection: A device attached to the system is not functioning. (0x1F) handshake failed; returned -1, SSL error code 1, net_error -101
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
browser = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()),
options=options)
browser.get('https://www.taobao.com')