
from math import sqrt
from joblib import Parallel, delayed11 多线程多进程异步
11.1 基础知识
11.1.1 阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续干别的事情,则称该程序在该操作上是阻塞的。
常见的阻塞形式有:网络 I/O 阻塞、磁盘 I/O 阻塞、用户输入阻塞等。阻塞是无处不在的,包括 CPU 切换上下文时,所有的进程都无法真正干事情,它们也会被阻塞。如果是多核 CPU,则正在执行上下文切换操作的核不可被利用。
11.1.2 非阻塞
程序在等待某操作的过程中,自身不被阻塞,可以继续运行干别的事情,则称该程序在该操作上是非阻塞的。
非阻塞并不是在任何程序级别、任何情况下都存在的。仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。
非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时与效率低下,我们才要把它变成非阻塞的。
11.1.3 同步
- concurrency
- parallel
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,此时这些程序单元是同步执行的。
例如在购物系统中更新商品库存时,需要用 “行锁” 作为通信信号,让不同的更新请求强制排队顺序执行,那更新库存的操作是同步的。
简言之,同步意味着有序。
11.1.4 异步
为了完成某个任务,有时不同程序单元之间无须通信协调也能完成任务,此时不相关的程序单元之间可以是异步的。
例如,爬取下载网页。调度程序调用下载程序后,即可调度其他任务,而无须与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无须相互通知协调。这些异步操作的完成时刻并不确定。
简言之,异步意味着无序。
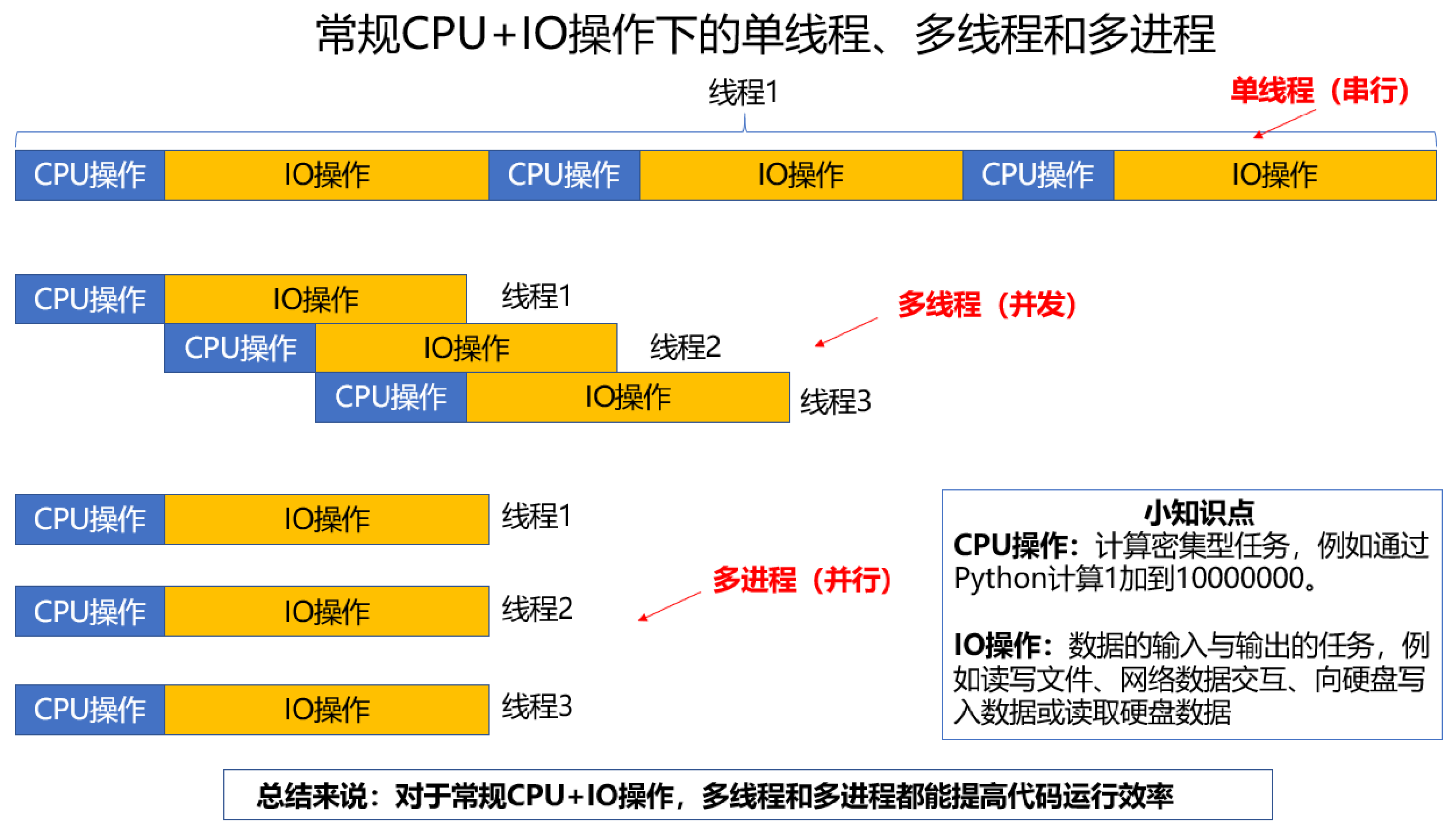
11.1.5 多进程多线程
多进程就是利用CPU的多核优势,在同一时间并行执行多个任务,可以大大提高执行效率。
Python 界有条不成文的准则: 计算密集型任务适合多进程,IO密集型任务适合多线程。
通常来说多线程相对于多进程有优势,因为创建一个进程开销比较大,然而因为在 python 中有 GIL(规定每个时刻单个CPU只能执行一个线程) 这把大锁的存在,导致执行计算密集型任务时多线程实际只能是单线程。 而且由于线程之间切换的开销导致多线程往往比实际的单线程还要慢,所以在 python 中计算密集型任务通常使用多进程,因为各个进程有各自独立的 GIL,互不干扰。
而在 IO 密集型任务中,CPU 时常处于等待状态,操作系统需要频繁与外界环境进行交互,如读写文件,在网络间通信等。在这期间 GIL 会被释放,因而就可以使用真正的多线程。
11.1.6 协程
协程,英文叫作 coroutine,又称微线程、纤程,它是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。
协程本质上是个单进程,它相对于多进程来说,无须线程上下文切换的开销,无须原子操作锁定及同步的开销,编程模型也非常简单。
我们可以使用协程来实现异步操作,比如在网络爬虫场景下,我们发出一个请求之后,需要等待一定时间才能得到响应,但其实在这个等待过程中,程序可以干许多其他事情,等到响应得到之后才切换回来继续处理,这样可以充分利用 CPU 和其他资源,这就是协程的优势。
11.2 多线程(threading)多进程(process)
python实现多线程(threading)多进程(process)的库有很多,我们这里介绍其中一种比较方便的方法。
11.2.1 joblib.Parallel
https://joblib.readthedocs.io/en/latest/generated/joblib.Parallel.html
Parallel(n_jobs=2, prefer="processes")(delayed(sqrt)(i**2) for i in range(10))[0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]a = Parallel(n_jobs=2, prefer="threads")(delayed(sqrt)(i**2) for i in range(10))
print(len(a))10%%time
from time import sleep
Parallel(n_jobs=1, prefer="threads", verbose=10)(delayed(sleep)(1) for _ in range(10))[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.9s remaining: 0.0s[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 1.9s remaining: 0.0s[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 2.9s remaining: 0.0s[Parallel(n_jobs=1)]: Done 4 out of 4 | elapsed: 3.9s remaining: 0.0s[Parallel(n_jobs=1)]: Done 5 out of 5 | elapsed: 4.9s remaining: 0.0s[Parallel(n_jobs=1)]: Done 6 out of 6 | elapsed: 5.9s remaining: 0.0s[Parallel(n_jobs=1)]: Done 7 out of 7 | elapsed: 7.0s remaining: 0.0s[Parallel(n_jobs=1)]: Done 8 out of 8 | elapsed: 8.0s remaining: 0.0s[Parallel(n_jobs=1)]: Done 9 out of 9 | elapsed: 9.0s remaining: 0.0sCPU times: total: 15.6 ms
Wall time: 10.1 s[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 10.0s finished[None, None, None, None, None, None, None, None, None, None]from heapq import nlargest
Parallel(n_jobs=2)(delayed(nlargest)(n, q)
for q in ([102,134,567], [1102,1134,1567])
for n in range(1,3))[[567], [567, 134], [1567], [1567, 1134]]progress bar
pip install tqdm_joblibfrom tqdm_joblib import tqdm_joblib
import pandas as pd
from dfply import diamonds
diamonds.head()| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
ll = diamonds.cut.tolist()
with tqdm_joblib(desc="Diamonds", total=len(ll)) as progress_bar:
a = Parallel(n_jobs=2)(delayed(lambda x: x.lower())(i) for i in ll)Diamonds: 0%| | 0/53940 [00:00<?, ?it/s]Diamonds: 11%|█▏ | 6140/53940 [00:00<00:00, 60852.80it/s]Diamonds: 27%|██▋ | 14332/53940 [00:00<00:00, 70898.21it/s]Diamonds: 46%|████▌ | 24572/53940 [00:00<00:00, 75887.95it/s]Diamonds: 61%|██████ | 32764/53940 [00:00<00:00, 74074.48it/s]Diamonds: 100%|██████████| 53940/53940 [00:00<00:00, 110143.05it/s]import urllib.request
URLS = ['https://www.baidu.com'] * 10
def load_url(url):
with urllib.request.urlopen(url) as conn:
return conn.statustry:
with tqdm_joblib(desc="Request Baidu", total=len(URLS)) as progress_bar:
a = Parallel(n_jobs=10, prefer="threads")(delayed(load_url)(i) for i in URLS)
print(a)
except Exception as e:
print(e)Request Baidu: 0%| | 0/10 [00:00<?, ?it/s]Request Baidu: 10%|█ | 1/10 [00:00<00:01, 8.49it/s]Request Baidu: 60%|██████ | 6/10 [00:00<00:00, 28.99it/s]Request Baidu: 100%|██████████| 10/10 [00:00<00:00, 33.62it/s]Request Baidu: 100%|██████████| 10/10 [00:00<00:00, 30.03it/s][200, 200, 200, 200, 200, 200, 200, 200, 200, 200]11.3 异步
11.3.1 asyncio
在介绍协程之前,我们先来看一个案例网站,链接地址为:https://httpbin.org/delay/2,如果我们访问这个链接,需要等待五秒之后才能得到结果,这是因为服务器强制等待了2秒的时间才返回响应。
平时我们浏览网页的时候,绝大部分网页响应速度还是很快的,如果我们写爬虫来爬取的话,发出 Request 到收到 Response 的时间不会很长,因此我们需要等待的时间并不多。
然而像上面这个网站,一次 Request 就需要2秒才能得到 Response,如果我们用 requests 写爬虫来爬取的话,那每次 requests 都要等待2秒才能拿到结果了。
import requests
import logging
import time
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')TOTAL_NUMBER = 5
URL = 'https://httpbin.org/delay/2'
start_time = time.time()
for _ in range(1, TOTAL_NUMBER + 1):
logging.info('scraping %s', URL)
response = requests.get(URL)
end_time = time.time()
logging.info('total time %s seconds', end_time - start_time)2023-04-25 23:57:39,196 - INFO: scraping https://httpbin.org/delay/22023-04-25 23:57:48,200 - INFO: scraping https://httpbin.org/delay/22023-04-25 23:57:52,522 - INFO: scraping https://httpbin.org/delay/22023-04-25 23:58:26,562 - INFO: scraping https://httpbin.org/delay/22023-04-25 23:58:32,776 - INFO: scraping https://httpbin.org/delay/22023-04-25 23:58:41,871 - INFO: total time 62.67459440231323 secondsPython 中使用协程最常用的库莫过于 asyncio,所以本节会以 asyncio 为基础来介绍协程的用法。
首先,我们需要了解下面几个概念:
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用对应的处理方法。
coroutine:中文翻译叫协程,在 Python 中常指代协程对象类型,我们可以将协程对象注册到时间循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态。
future:代表将来执行或没有执行的任务的结果,实际上和 task 没有本质区别。
另外,我们还需要了解 async/await 关键字,专门用于定义协程。其中,async 定义一个协程,await 用来挂起阻塞方法的执行。
nest-asyncio
use nest-asyncio
By design asyncio does not allow its event loop to be nested. This presents a practical problem: When in an environment where the event loop is already running it’s impossible to run tasks and wait for the result. Trying to do so will give the error “RuntimeError: This event loop is already running”. … This module patches asyncio to allow nested use of asyncio.run and loop.run_until_complete. Source: <pypi.org/project/nest-asyncio>
import nest_asyncio
nest_asyncio.apply()11.3.2 aiohttp 异步
import aiohttp
import asyncio
import time
async def fetch_page(url):
page_start = time.time()
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
print(f'Page took {time.time() - page_start}')
async def main():
tasks = [fetch_page('http://books.toscrape.com') for i in range(10)]
await asyncio.gather(*tasks)
start_time = time.time()
asyncio.run(main())
print(f'All took {time.time() - start_time}')Page took 0.5220553874969482
Page took 0.5396015644073486
Page took 0.6004831790924072
Page took 0.6416120529174805
Page took 0.6867837905883789
Page took 0.691220760345459
Page took 0.69960618019104Page took 0.7500481605529785
Page took 0.7678792476654053
Page took 0.8740057945251465
All took 0.8760044574737549import aiohttp
import asyncio
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://httpbin.org/post', data=data) as response:
print('status:', response.status)
print('headers:', response.headers)
print('body:', await response.text())
print('bytes:', await response.read())
print('json:', await response.json())
if __name__ == '__main__':
asyncio.run(main())status: 200
headers: <CIMultiDictProxy('Date': 'Tue, 25 Apr 2023 15:58:47 GMT', 'Content-Type': 'application/json', 'Content-Length': '504', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>
body: {
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python/3.9 aiohttp/3.8.3",
"X-Amzn-Trace-Id": "Root=1-6447f8b5-1ae321e61ce143a76ea50ee7"
},
"json": null,
"origin": "219.136.128.171",
"url": "https://httpbin.org/post"
}
bytes: b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "age": "25", \n "name": "germey"\n }, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Content-Length": "18", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "Python/3.9 aiohttp/3.8.3", \n "X-Amzn-Trace-Id": "Root=1-6447f8b5-1ae321e61ce143a76ea50ee7"\n }, \n "json": null, \n "origin": "219.136.128.171", \n "url": "https://httpbin.org/post"\n}\n'
json: {'args': {}, 'data': '', 'files': {}, 'form': {'age': '25', 'name': 'germey'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '18', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'Python/3.9 aiohttp/3.8.3', 'X-Amzn-Trace-Id': 'Root=1-6447f8b5-1ae321e61ce143a76ea50ee7'}, 'json': None, 'origin': '219.136.128.171', 'url': 'https://httpbin.org/post'}这里我们可以看到有些字段前面需要加 await,有的则不需要。其原则是,如果它返回的是一个 coroutine 对象(如 async 修饰的方法),那么前面就要加 await,具体可以看 aiohttp 的 API,其链接为:https://docs.aiohttp.org/en/stable/client_reference.html
Time Out
对于超时设置,我们可以借助 ClientTimeout 对象,比如这里要设置 1 秒的超时,可以这么实现:
import aiohttp
import asyncio
async def main():
timeout = aiohttp.ClientTimeout(total=4)
try:
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get('https://httpbin.org/get') as response:
print('status:', response.status)
except Exception:
pass
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())status: 200如果超时的话,会抛出 TimeoutError 异常,其类型为 asyncio.TimeoutError,我们再进行异常捕获即可。
并发限制
由于 aiohttp 可以支持非常大的并发,比如上万、十万、百万都是能做到的,但对于这么大的并发量,目标网站很可能在短时间内无法响应,而且很可能瞬时间将目标网站爬挂掉,所以我们需要控制一下爬取的并发量。
网络爬虫在抓取网页的数据时,可能会出现这样的情况:起初可以正常抓取网页的数据,一段时间后便不能继续抓取了,可能会收到403错误及提示信息“您的IP访问频率过高”。之所以出现这种现象是因为网站采取了防爬虫措施,该网站会检测某个IP地址在单位时间内访问的次数,如果超过其设定的阈值,就会直接拒绝为拥有该IP地址的客户端服务,这种情况称为封IP。
一般情况下,我们可以借助于 asyncio 的 Semaphore 来控制并发量,示例如下:
import asyncio
import aiohttp
CONCURRENCY = 5
URL = 'https://www.baidu.com'
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
async def scrape_api():
async with semaphore:
print('scraping', URL)
async with session.get(URL) as response:
await asyncio.sleep(2)
return await response.text()
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(scrape_api()) for _ in range(15)]
await asyncio.gather(*scrape_index_tasks)
if __name__ == '__main__':
asyncio.run(main())scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.comscraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.comscraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com
scraping https://www.baidu.com这里我们声明了 CONCURRENCY(代表爬取的最大并发量)为 5,同时声明爬取的目标 URL 为百度。接着,我们借助于 Semaphore 创建了一个信号量对象,将其赋值为 semaphore,这样我们就可以用它来控制最大并发量了。怎么使用呢?这里我们把它直接放置在对应的爬取方法里面,使用 async with 语句将 semaphore 作为上下文对象即可。这样的话,信号量可以控制进入爬取的最大协程数量,即我们声明的 CONCURRENCY 的值。
11.3.3 httpx异步
https://www.python-httpx.org/async/
import httpx
import asyncio
async def main():
async with httpx.AsyncClient(http2=True) as client:
response = await client.get('https://httpbin.org/get')
print(response.text)
asyncio.run(main())import httpx
import asyncio
async def fetch(url):
async with httpx.AsyncClient(http2=True) as client:
response = await client.get(url)
print(response.text)
if __name__ == '__main__':
asyncio.run(fetch('https://httpbin.org/get'))import httpx
import asyncio
import time
async def fetch_page(url):
page_start = time.time()
async with httpx.AsyncClient() as client:
response = await client.get(url)
print(f'Page took {time.time() - page_start}')
async def main():
tasks = [fetch_page('http://books.toscrape.com') for _ in range(10)]
await asyncio.gather(*tasks)
start_time = time.time()
asyncio.run(main())
print(f'All took {time.time() - start_time}')