8 基本库的使用
最基础的 HTTP 库有 urllib, requests, httpx。
8.1 urllib应用
我们来了解一下 urllib 库的使用方法,它是 Python 内置的 HTTP 请求库,也就是说不需要额外安装即可使用。它包含如下 4 个模块。
- request:它是最基本的 HTTP 请求模块,可以用来模拟发送请求。就像在浏览器里输入网址然后回车一样,只需要给库方法传入 URL 以及额外的参数,就可以模拟实现这个过程了。
- error:异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作以保证程序不会意外终止。
- parse:一个工具模块,提供了许多 URL 处理方法,比如拆分、解析和合并等。
- robotparser:主要用来识别网站的
robots.txt文件,然后判断哪些网站可以爬,哪些网站不可以爬,它其实用得比较少。
8.1.1 发送请求
使用 urllib 的 request 模块,我们可以方便地实现请求的发送并得到响应。本节就来看下它的具体用法。
urlopen
urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理授权验证(authentication)、重定向(redirection)、浏览器 Cookies 以及其他内容。
下面我们来看一下它的强大之处。这里以 Python 官网为例,我们来把这个网页抓下来:
import urllib.request
from pprint import pprint
response = urllib.request.urlopen('https://www.jnu.edu.cn/main.htm')
pprint(response.read().decode('utf-8')[:1000])利用 type 方法输出响应的类型:
print(type(response))它是一个 HTTPResposne 类型的对象,主要包含 read、readinto、getheader、getheaders、fileno 等方法,以及 msg、version、status、reason、debuglevel、closed 等属性。
下面再通过一个实例来看看:
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))利用最基本的 urlopen 方法,可以完成最基本的简单网页的 GET 请求抓取。
data参数
data 参数是可选的。如果要添加该参数,需要使用 bytes 方法将参数转化为字节流编码格式的内容,即 bytes 类型。另外,如果传递了这个参数,则它的请求方式就不再是 GET 方式,而是 POST 方式。
下面用实例来看一下:
https://httpbin.org/forms/post
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'name': 'tony'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read().decode('utf-8'))这里我们传递了一个参数’name’: ‘tony’。它需要被转码成 bytes(字节流)类型。其中转字节流采用了 bytes 方法,该方法的第一个参数需要是 str(字符串)类型,需要用 urllib.parse 模块里的 urlencode 方法来将参数字典转化为字符串;第二个参数指定编码格式,这里指定为 utf8。
在这里请求的站点是 httpbin.org,它可以提供 HTTP 请求测试,本次我们请求的 URL 为:http://httpbin.org/post,这个链接可以用来测试 POST 请求,它可以输出 Request 的一些信息,其中就包含我们传递的 data 参数。
timeout 参数
timeout 参数用于设置超时时间,单位为秒,意思就是如果请求超出了设置的这个时间,还没有得到响应,就会抛出异常。如果不指定该参数,就会使用全局默认时间。它支持 HTTP、HTTPS、FTP 请求。
下面用实例来看一下:
import urllib.request
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=10)
print(response.read())
except Exception:
pass因此,可以通过设置这个超时时间来控制一个网页如果长时间未响应,就跳过它的抓取。这可以利用 try except 语句来实现,相关代码如下:
import socket
import urllib.request
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout = 0.1)
except Exception as e:
if isinstance(e, socket.timeout):
print('TIME OUT')在这里我们请求了 http://httpbin.org/get 这个测试链接,设置了超时时间是 0.1 秒,然后捕获了 URLError 这个异常,然后判断异常原因是 socket.timeout 类型,意思就是超时异常,就得出它确实是因为超时而报错,打印输出了 TIME OUT。
Request
我们知道利用 urlopen 方法可以实现最基本请求的发起,但这几个简单的参数并不足以构建一个完整的请求。如果请求中需要加入 Headers 等信息,就可以利用更强大的 Request 类来构建。
首先,我们用实例来感受一下 Request 的用法:
import urllib.request
request = urllib.request.Request('https://www.jnu.edu.cn/main.htm')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8')[:500])可以发现,我们依然是用 urlopen 方法来发送这个请求,只不过这次该方法的参数不再是 URL,而是一个 Request 类型的对象。通过构造这个数据结构,一方面我们可以将请求独立成一个对象,另一方面可更加丰富和灵活地配置参数。
下面我们看一下 Request 可以通过怎样的参数来构造,它的构造方法如下:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)第一个参数 url 用于请求 URL,这是必传参数,其他都是可选参数。
第二个参数 data 如果要传,必须传 bytes(字节流)类型的。如果它是字典,可以先用 urllib.parse 模块里的 urlencode() 编码。
第三个参数 headers 是一个字典,它就是请求头,我们可以在构造请求时通过 headers 参数直接构造,也可以通过调用请求实例的 add_header() 方法添加。
- 添加请求头最常用的用法就是通过修改 User-Agent 来伪装浏览器,默认的 User-Agent 是
Python-urllib,我们可以通过修改它来伪装浏览器。比如要伪装火狐浏览器,你可以把它设置为:Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
- 添加请求头最常用的用法就是通过修改 User-Agent 来伪装浏览器,默认的 User-Agent 是
第四个参数 origin_req_host 指的是请求方的 host 名称或者 IP 地址。
第五个参数 unverifiable 表示这个请求是否是无法验证的,默认是 False,意思就是说用户没有足够权限来选择接收这个请求的结果。例如,我们请求一个 HTML 文档中的图片,但是我们没有自动抓取图像的权限,这时 unverifiable 的值就是 True。
第六个参数 method 是一个字符串,用来指示请求使用的方法,比如 GET、POST 和 PUT 等。
下面我们传入多个参数构建请求来看一下:
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {'name': 'Germey'}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))观察结果可以发现,我们成功设置了 data、headers 和 method。
另外,headers 也可以用 add_header 方法来添加:
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')如此一来,我们就可以更加方便地构造请求,实现请求的发送啦。
验证
有些网站在打开时就会弹出提示框,直接提示你输入用户名和密码,验证成功后才能查看页面
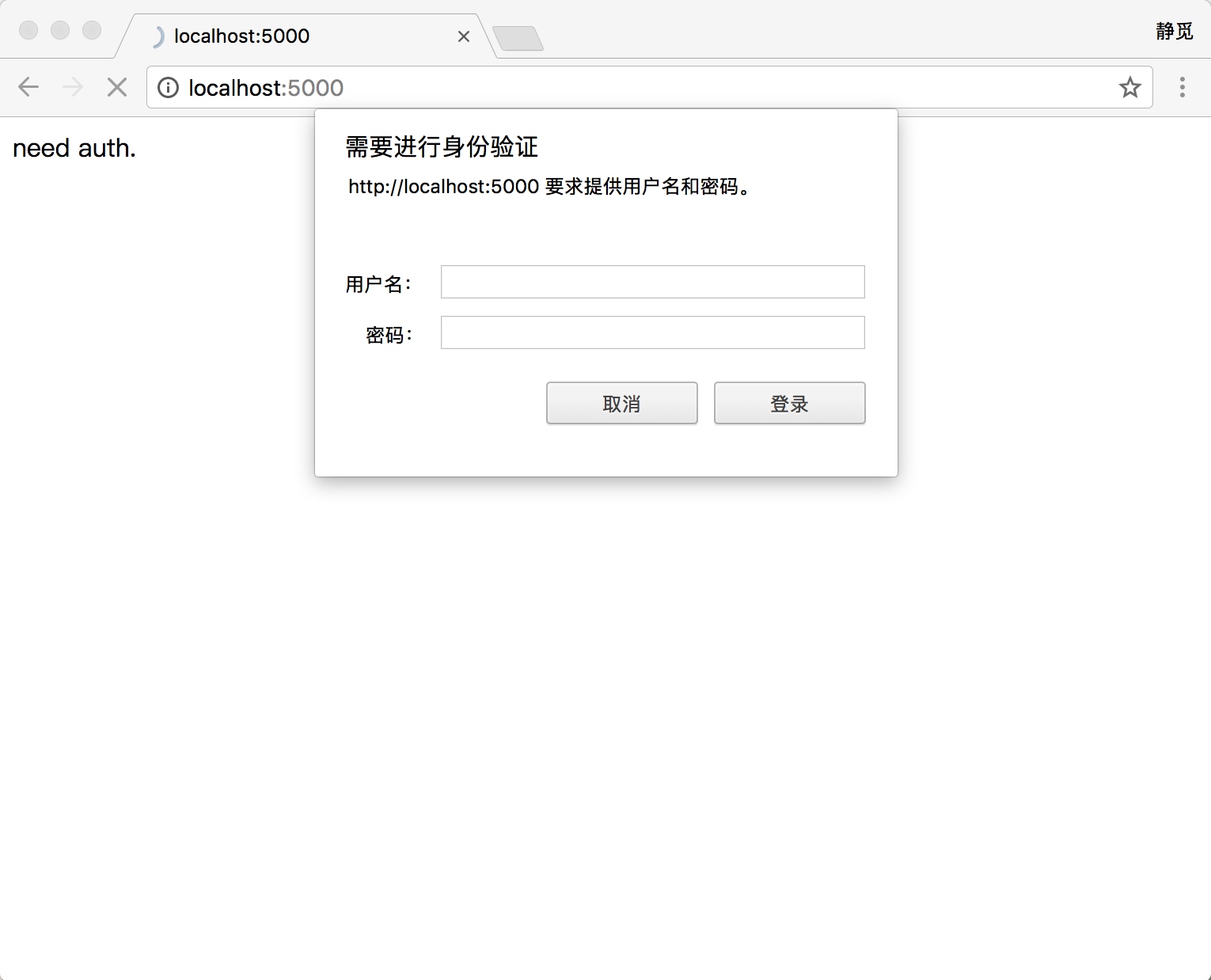
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = 'admin'
password = 'admin'
url = 'http://ssr3.scrape.center/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf-8')
print(html[:500])
except URLError as e:
print(e.reason)这里首先实例化 HTTPBasicAuthHandler 对象,其参数是 HTTPPasswordMgrWithDefaultRealm 对象,它利用 add_password 方法添加进去用户名和密码,这样就建立了一个处理验证的 Handler。
8.1.2 解析链接
前面说过,urllib 库里还提供了 parse 模块,它定义了处理 URL 的标准接口,例如实现 URL 各部分的抽取、合并以及链接转换。它支持如下协议的 URL 处理:file、ftp、gopher、hdl、http、https、imap、mailto、 mms、news、nntp、prospero、rsync、rtsp、rtspu、sftp、 sip、sips、snews、svn、svn+ssh、telnet 和 wais。本节中,我们介绍一下该模块中常用的方法来看一下它的便捷之处。
urlparse
该方法可以实现 URL 的识别和分段,这里先用一个实例来看一下:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)这里我们利用 urlparse 方法进行了一个 URL 的解析。首先,输出了解析结果的类型,然后将结果也输出出来。
可以看到,返回结果是一个 ParseResult 类型的对象,它包含 6 个部分,分别是 scheme、netloc、path、params、query 和 fragment。
观察一下该实例的 URL:
scheme://netloc/path;params?query#fragment可以发现,urlparse 方法将其拆分成了 6 个部分。大体观察可以发现,解析时有特定的分隔符。比如,:// 前面的就是 scheme,代表协议;第一个 / 符号前面便是 netloc,即域名,后面是 path,即访问路径;分号;后面是 params,代表参数;问号?后面是查询条件 query,一般用作 GET 类型的 URL;井号 #后面是锚点,用于直接定位页面内部的下拉位置。
一个标准的 URL 都会符合这个规则,利用 urlparse 方法可以将它拆分开来。
除了这种最基本的解析方式外,urlparse 方法还有其他配置吗?接下来,看一下它的 API 用法:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)- urlstring:这是必填项,即待解析的 URL。
- scheme:它是默认的协议(比如 http 或 https 等)。假如这个链接没有带协议信息,会将这个作为默认的协议。我们用实例来看一下
- allow_fragments:即是否忽略 fragment。如果它被设置为 False,fragment 部分就会被忽略,它会被解析为 path、parameters 或者 query 的一部分,而 fragment 部分为空。
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)下面我们用实例来看一下:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result)返回结果 ParseResult 实际上是一个元组,我们可以用索引顺序来获取,也可以用属性名获取。示例如下:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result.scheme, result[0], result.netloc, result[1], sep='\n')可以发现,二者的结果是一致的,两种方法都可以成功获取。
urlunparse
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))这样我们就成功实现了 URL 的构造。
urljoin
此外,生成链接还有另一个方法,那就是 urljoin 方法。我们可以提供一个 base_url(基础链接)作为第一个参数,将新的链接作为第二个参数,该方法会分析 base_url 的 scheme、netloc 和 path 这 3 个内容并对新链接缺失的部分进行补充,最后返回结果。
下面通过几个实例看一下:
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com', 'FAQ.html'))
print(urljoin('http://www.baidu.com', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc', 'https://cuiqingcai.com/index.php'))
print(urljoin('http://www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))可以发现,base_url 提供了三项内容 scheme、netloc 和 path。如果这 3 项在新的链接里不存在,就予以补充;如果新的链接存在,就使用新的链接的部分。而 base_url 中的 params、query 和 fragment 是不起作用的。
通过 urljoin 方法,我们可以轻松实现链接的解析、拼合与生成。
urlencode
这里我们再介绍一个常用的方法 ——urlencode,它在构造 GET 请求参数的时候非常有用,示例如下:
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)这里首先声明了一个字典来将参数表示出来,然后调用 urlencode 方法将其序列化为 GET 请求参数。
可以看到,参数就成功地由字典类型转化为 GET 请求参数了。
这个方法非常常用。有时为了更加方便地构造参数,我们会事先用字典来表示。要转化为 URL 的参数时,只需要调用该方法即可。
parse_qs
有了序列化,必然就有反序列化。如果我们有一串 GET 请求参数,利用 parse_qs 方法,就可以将它转回字典,示例如下:
from urllib.parse import parse_qs
query = 'name=germey&age=22'
print(parse_qs(query))parse_qsl
另外,还有一个 parse_qsl 方法,它用于将参数转化为元组组成的列表,示例如下:
from urllib.parse import parse_qsl
query = 'name=germey&age=22'
print(parse_qsl(query))quote
该方法可以将内容转化为 URL 编码的格式。URL 中带有中文参数时,有时可能会导致乱码的问题,此时用这个方法可以将中文字符转化为 URL 编码,示例如下:
from urllib.parse import quote
keyword = ' 壁纸 '
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url)unquote
有了 quote 方法,当然还有 unquote 方法,它可以进行 URL 解码,示例如下:
from urllib.parse import unquote
url = 'https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))8.1.3 分析 Robots 协议
Robots 协议也称作爬虫协议、机器人协议,它的全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫作 robots.txt 的文本文件,一般放在网站的根目录下。
下面我们看一个 robots.txt 的样例:
User-agent: *
Disallow: /
Allow: /public/这实现了对所有搜索爬虫只允许爬取 public 目录的功能,将上述内容保存成 robots.txt 文件,放在网站的根目录下,和网站的入口文件(比如 index.php、index.html 和 index.jsp 等)放在一起。
上面的 User-agent 描述了搜索爬虫的名称,这里将其设置为 * 则代表该协议对任何爬取爬虫有效。比如,我们可以设置:
User-agent: Baiduspider这就代表我们设置的规则对百度爬虫是有效的。如果有多条 User-agent 记录,则就会有多个爬虫会受到爬取限制,但至少需要指定一条。
了解 Robots 协议之后,我们就可以使用 robotparser 模块来解析 robots.txt 了。该模块提供了一个类 RobotFileParser,它可以根据某网站的 robots.txt 文件来判断一个爬取爬虫是否有权限来爬取这个网页。
该类用起来非常简单,只需要在构造方法里传入 robots.txt 的链接即可。首先看一下它的声明:
urllib.robotparser.RobotFileParser(url='')当然,也可以在声明时不传入,默认为空,最后再使用 set_url() 方法设置一下也可。
下面列出了这个类常用的几个方法。
set_url :用来设置 robots.txt 文件的链接。如果在创建 RobotFileParser 对象时传入了链接,那么就不需要再使用这个方法设置了。
read:读取 robots.txt 文件并进行分析。注意,这个方法执行一个读取和分析操作,如果不调用这个方法,接下来的判断都会为 False,所以一定记得调用这个方法。这个方法不会返回任何内容,但是执行了读取操作。
parse:用来解析 robots.txt 文件,传入的参数是 robots.txt 某些行的内容,它会按照 robots.txt 的语法规则来分析这些内容。
can_fetch:该方法传入两个参数,第一个是 User-agent,第二个是要抓取的 URL。返回的内容是该搜索引擎是否可以抓取这个 URL,返回结果是 True 或 False。
mtime:返回的是上次抓取和分析 robots.txt 的时间,这对于长时间分析和抓取的搜索爬虫是很有必要的,你可能需要定期检查来抓取最新的 robots.txt。
modified:它同样对长时间分析和抓取的搜索爬虫很有帮助,将当前时间设置为上次抓取和分析 robots.txt 的时间。
下面我们用实例来看一下:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url('http://www.jianshu.com/robots.txt')
rp.read()
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
print(rp.can_fetch('*', "http://www.jianshu.com/search?q=python&page=1&type=collections"))这里以简书为例,首先创建 RobotFileParser 对象,然后通过 set_url 方法设置了robots.txt 的链接。
8.2 requests应用
为了更加方便地实现这些操作,就有了更为强大的库 requests,有了它,Cookie、登录验证、代理设置等操作都不是事儿。
8.2.1 准备工作
在开始之前,请确保已经正确安装好了 requests 库,如尚未安装可以使用 pip3 来安装:
pip3 install requests8.2.2 实例引入
urllib 库中的 urlopen 方法实际上是以 GET 方式请求网页,而 requests 中相应的方法就是 get 方法,是不是感觉表达更明确一些?下面通过实例来看一下:
import requests
try:
r = requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text)
print(r.cookies)
except Exception as e:
print(e)这里我们调用 get 方法实现与 urlopen 相同的操作,得到一个 Response 对象,然后分别输出了 Response 的类型、状态码、响应体的类型、内容以及 Cookies。
通过运行结果可以发现,它的返回类型是 requests.models.Response,响应体的类型是字符串 str,Cookies 的类型是 RequestsCookieJar。
使用 get 方法成功实现一个 GET 请求,这倒不算什么,更方便之处在于其他的请求类型依然可以用一句话来完成,示例如下:
r = requests.post('http://httpbin.org/post')
r = requests.put('http://httpbin.org/put')
r = requests.delete('http://httpbin.org/delete')
r = requests.head('http://httpbin.org/get')
r = requests.options('http://httpbin.org/get')这里分别用 post、put、delete 等方法实现了 POST、PUT、DELETE 等请求。
其实这只是冰山一角,更多的还在后面。
8.2.3 GET 请求
HTTP 中最常见的请求之一就是 GET 请求,下面首先来详细了解一下利用 requests 构建 GET 请求的方法。
基本实例
首先,构建一个最简单的 GET 请求,请求的链接为 http://httpbin.org/get,该网站会判断如果客户端发起的是 GET 请求的话,它返回相应的请求信息:
import requests
r = requests.get('http://httpbin.org/get')
print(r.text)print(r.json())import json
with open('data/test_data.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(r.json()))import json
data = json.load(open('data/test_data.json', encoding='utf-8'))
data["headers"]["User-Agent"]data["headers"].get("User-Agents", "If not exist, display this")可以发现,我们成功发起了 GET 请求,返回结果中包含请求头、URL、IP 等信息。
那么,对于 GET 请求,如果要附加额外的信息,一般怎样添加呢?比如现在想添加两个参数,其中 name 是 germey,age 是 22。要构造这个请求链接,是不是要直接写成:
r = requests.get('http://httpbin.org/get?name=germey&age=22')一般情况下,这种信息数据会用字典来存储。
这同样很简单,利用 params 这个参数就好了,示例如下:
import requests
data = {
'name': 'germey',
'age': 22
}
r = requests.get("http://httpbin.org/get", params=data)
print(r.text)通过返回信息我们可以判断,请求的链接自动被构造成了:http://httpbin.org/get?age=22&name=germey。
另外,网页的返回类型实际上是 str 类型,但是它很特殊,是 JSON 格式的。所以,如果想直接解析返回结果,得到一个字典格式的话,可以直接调用 json 方法。示例如下:
import requests
r = requests.get("http://httpbin.org/get")
print(type(r.text))
print(r.json())
print(type(r.json()))可以发现,调用 json 方法,就可以将返回结果是 JSON 格式的字符串转化为字典。
抓取网页
上面的请求链接返回的是 JSON 形式的字符串,那么如果请求普通的网页,则肯定能获得相应的内容了。
import requests
import re
r = requests.get('https://ssr1.scrape.center/')
pattern = re.compile('<h2.*?>(.*?)</h2>', re.S)
titles = re.findall(pattern, r.text)
print(titles)import requests
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
url = 'https://book.douban.com/tag/小说?start=20&type=T'
resp = requests.get(url,
headers = headers
)
respfrom pathlib import Path
Path("data/sample1.html").write_text(resp.text)另一种方法
with open("data/sample2.html", "w+", encoding = "utf-8") as file:
file.write(resp.text)我们发现,这里成功提取出了所有的问题内容。
我们发现,这里成功提取出了所有的电影标题,一个最基本的抓取和提取流程就完成了。
抓取二进制数据
在上面的例子中,我们抓取的是网站的一个页面,实际上它返回的是一个 HTML 文档。如果想抓取图片、音频、视频等文件,应该怎么办呢?
图片、音频、视频这些文件本质上都是由二进制码组成的,由于有特定的保存格式和对应的解析方式,我们才可以看到这些形形色色的多媒体。所以,想要抓取它们,就要拿到它们的二进制数据。
下面以示例网站的站点图标为例来看一下:
import requests
r = requests.get('https://scrape.center/favicon.ico')
print(r.text[:100])print(r.content[:100])这里打印了 Response 对象的两个属性,一个是 text,另一个是 content。
可以注意到,前者出现了乱码,后者结果前带有一个 b,这代表是 bytes 类型的数据。由于图片是二进制数据,所以前者在打印时转化为 str 类型,也就是图片直接转化为字符串,这理所当然会出现乱码。
上面返回的结果我们并不能看懂,它实际上是图片的二进制数据,没关系,我们将刚才提取到的信息保存下来就好了,代码如下:
import requests
r = requests.get('https://scrape.center/favicon.ico')
with open('./data/favicon.ico', 'wb') as f:
f.write(r.content)这里用了 open 方法,它的第一个参数是文件名称,第二个参数代表以二进制写的形式打开,可以向文件里写入二进制数据。
运行结束之后,可以发现在文件夹中出现了名为 favicon.ico 的图标。
r = requests.get('https://img9.doubanio.com/view/subject/s/public/s34035255.jpg')
with open('data/潮汐图.jpg', 'wb') as f:
f.write(r.content)r = requests.get('http://static.cninfo.com.cn/finalpage/2023-02-23/1215943577.PDF')
with open('data/1215943577.PDF', 'wb') as f:
f.write(r.content)添加 headers
使用 headers 参数设置请求头 Request Headers。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
r = requests.get('https://ssr1.scrape.center/', headers=headers)
print(r.text[:500])当然,我们可以在 headers 这个参数中任意添加其他的字段信息。
8.2.4 POST 请求
前面我们了解了最基本的 GET 请求,另外一种比较常见的请求方式是 POST。使用 requests 实现 POST 请求同样非常简单,示例如下:
import requests
data = {'name': 'germey', 'age': '25'}
r = requests.post("https://httpbin.org/post", data=data)
print(r.text)这里还是请求 https://httpbin.org/post,该网站可以判断如果请求是 POST 方式,就把相关请求信息返回。
可以发现,我们成功获得了返回结果,其中 form 部分就是提交的数据,这就证明 POST 请求成功发送了。
8.2.5 响应
发送请求后,得到的自然就是响应。在上面的实例中,我们使用 text 和 content 获取了响应的内容。此外,还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookie 等。示例如下:
import requests
r = requests.get('https://ssr1.scrape.center/')
print(type(r.status_code), r.status_code)
print(type(r.headers), r.headers)
print(type(r.cookies), r.cookies)
print(type(r.url), r.url)
print(type(r.history), r.history)8.2.6 高级用法
前面我们了解了 requests 的基本用法,如基本的 GET、POST 请求以及 Response 对象。下面我们再来了解下 requests 的一些高级用法,如文件上传、Cookie 设置、代理设置等。
文件上传
我们知道 requests 可以模拟提交一些数据。假如有的网站需要上传文件,我们也可以用它来实现,这非常简单,示例如下:
import requests
files = {'file': open('data/favicon.ico', 'rb')}
r = requests.post('https://httpbin.org/post', files=files)
print(r.text)在前一节中我们保存了一个文件 favicon.ico,这次用它来模拟文件上传的过程。需要注意的是,favicon.ico 需要和当前脚本在同一目录下。如果有其他文件,当然也可以使用其他文件来上传,更改下代码即可。
Cookie 设置
前面我们使用 urllib 处理过 Cookie,写法比较复杂,而有了 requests,获取和设置 Cookie 只需一步即可完成。
我们先用一个实例看一下获取 Cookie 的过程:
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)这里我们首先调用 cookies 属性即可成功得到 Cookie,可以发现它是 RequestCookieJar 类型。然后用 items 方法将其转化为元组组成的列表,遍历输出每一个 Cookie 条目的名称和值,实现 Cookie 的遍历解析。
当然,我们也可以直接用 Cookie 来维持登录状态,下面我们以 知乎 为例来说明一下,首先我们登录 知乎,然后将 Headers 中的 Cookie 内容复制下来,如图所示。
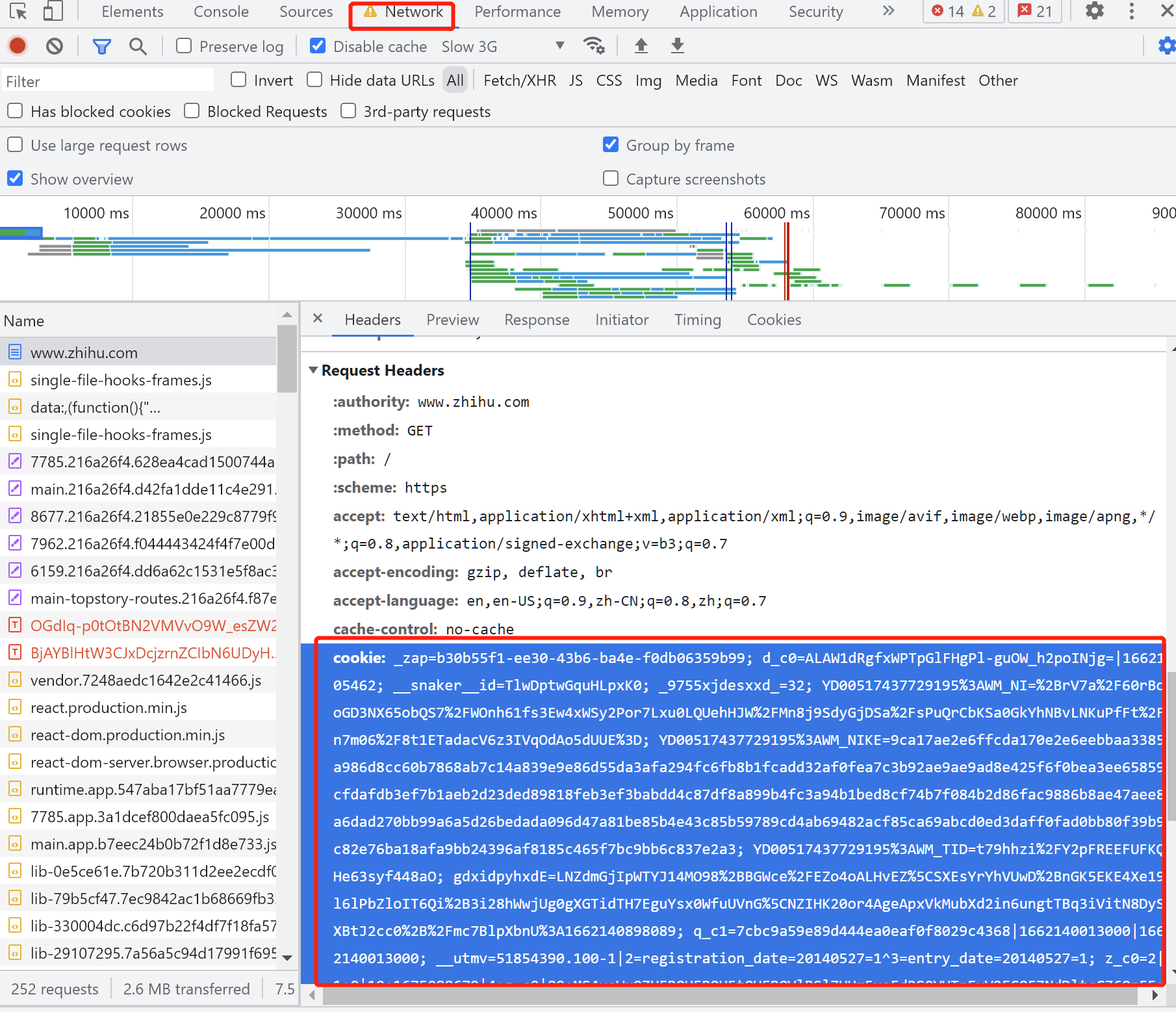
这里可以替换成你自己的 Cookie,将其设置到 Headers 里面,然后发送请求,示例如下:
import requests
headers = {
'Cookie': '_zap=b30b55f1-ee30-43b6-ba4e-f0db06359b99; d_c0=ALAW1dRgfxWPTpGlFHgPl-guOW_h2poINjg=|1662105462; __snaker__id=TlwDptwGquHLpxK0; _9755xjdesxxd_=32',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
}
r = requests.get('https://www.zhihu.com/', headers=headers)from pathlib import Path
Path("data/zhihu.html").write_text(r.text)得到这样类似的结果,就说明我们用 Cookie 就成功模拟了登录状态,这样我们就能爬取登录之后才能看到的页面了。
当然,我们也可以通过 cookies 参数来设置 Cookie 的信息,这里我们可以构造一个 RequestsCookieJar 对象,然后把刚才复制的 Cookie 处理下并赋值,示例如下:
import requests
cookies = headers['Cookie']
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get('https://www.zhihu.com/', cookies=jar, headers=headers)
Path("data/zhihu.html").write_text(r.text)这里我们首先新建了一个 RequestCookieJar 对象,然后将复制下来的 cookies 利用 split 方法分割,接着利用 set 方法设置好每个 Cookie 的 key 和 value,然后通过调用 requests 的 get 方法并传递给 cookies 参数即可。
测试后,发现同样可以正常登录。
Session 维持
在 requests 中,如果直接利用 get 或 post 等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的 Session,也就是说相当于你用了两个浏览器打开了不同的页面。
设想这样一个场景,第一个请求利用 requests 的 post 方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,又用了一次 requests 的 get 方法去请求个人信息页面。
实际上,这相当于打开了两个浏览器,是两个完全独立的操作,对应两个完全不相关的 Session.
其实解决这个问题的主要方法就是维持同一个 Session,也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器。
我们可以方便地维护一个 Session,而且不用担心 Cookie 的问题,它会帮我们自动处理好。
我们先做一个小实验吧,如果沿用之前的写法,示例如下:
import requests
requests.get('https://httpbin.org/cookies/set/number/123456789')
r = requests.get('https://httpbin.org/cookies')
print(r.text)这里我们请求了一个测试网址 https://httpbin.org/cookies/set/number/123456789。请求这个网址时,可以设置一个Cookie 条目,名称叫作 number,内容是 123456789,随后又请求了 https://httpbin.org/cookies,此网址可以获取当前的 Cookie 信息。
这时候,我们再用刚才所说的 Session 试试看:
import requests
s = requests.Session()
s.get('https://httpbin.org/cookies/set/number/123456789')
r = s.get('https://httpbin.org/cookies')
print(r.text)这些可以看到 Cookies 被成功获取了!这下能体会到同一个会话和不同会话的区别了吧!
利用 Session,可以做到模拟同一个会话而不用担心 Cookie 的问题。它通常用于模拟登录成功之后再进行下一步的操作。 Session 在平常用得非常广泛,可以用于模拟在一个浏览器中打开同一站点的不同页面,后面会有专门的章节来讲解这部分内容。
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能收到响应,甚至到最后收不到响应而报错。为了防止服务器不能及时响应,应该设置一个超时时间,即超过了这个时间还没有得到响应,那就报错。这需要用到 timeout 参数。这个时间的计算是发出请求到服务器返回响应的时间。示例如下:
import requests
r = requests.get('https://httpbin.org/get', timeout=10)
print(r.status_code)通过这样的方式,我们可以将超时时间设置为 1 秒,如果 1 秒内没有响应,那就抛出异常。
身份认证
这个网站就是启用了基本身份认证,在上一节中我们可以利用 urllib 来实现身份的校验,但实现起来相对繁琐。
我们可以使用 requests 自带的身份认证功能,通过 auth 参数即可设置,示例如下:
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('https://ssr3.scrape.center/', auth=HTTPBasicAuth('admin', 'admin'))
print(r.status_code)这个示例网站的用户名和密码都是 admin,在这里我们可以直接设置。
如果用户名和密码正确的话,请求时就会自动认证成功,会返回 200 状态码;如果认证失败,则返回 401 状态码。
当然,如果参数都传一个 HTTPBasicAuth 类,就显得有点烦琐了,所以 requests 提供了一个更简单的写法,可以直接传一个元组,它会默认使用 HTTPBasicAuth 这个类来认证。
import requests
r = requests.get('https://ssr3.scrape.center/', auth=('admin', 'admin'))
print(r.status_code)8.3 正则表达式
正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了。例如,这里输入待匹配的文本,具体如下:
Hello, my phone number is 010-86432100 and email is cqc@cuiqingcai.com, and my website is https://www.xxxx.com对于 URL 来说,可以用下面的正则表达式匹配:
[a-zA-z]+://[^\s]*用这个正则表达式去匹配一个字符串,如果这个字符串中包含类似 URL 的文本,那就会被提取出来。
8.3.1 match
这里首先介绍第一个常用的匹配方法 —— match,向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否匹配字符串。
match 方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回 None。示例如下:
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
print(result.group())
print(result.span())这里首先声明了一个字符串,其中包含英文字母、空白字符、数字等。接下来,我们写一个正则表达式:
^Hello\s\d\d\d\s\d{4}\s\w{10}用它来匹配这个长字符串。开头的 ^ 是匹配字符串的开头,也就是以 Hello 开头;然后 匹配空白字符,用来匹配目标字符串的空格;配数字,3 个 配 123;然后再写 1 个 匹配空格;后面还有 4567,我们其实可以依然用 4 个 匹配,但是这么写比较烦琐,所以后面可以跟 {4} 以代表匹配前面的规则 4 次,也就是匹配 4 个数字;然后后面再紧接 1 个空白字符,最后 匹配 10 个字母及下划线。我们注意到,这里其实并没有把目标字符串匹配完,不过这样依然可以进行匹配,只不过匹配结果短一点而已。
匹配目标
刚才我们用 match 方法可以得到匹配到的字符串内容,但是如果想从字符串中提取一部分内容,该怎么办呢?就像最前面的实例一样,从一段文本中提取出邮件或电话号码等内容。
这里可以使用 () 括号将想提取的子字符串括起来。() 实际上标记了一个子表达式的开始和结束位置,被标记的每个子表达式会依次对应每一个分组,调用 group 方法传入分组的索引即可获取提取的结果。示例如下:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())可以看到,我们成功得到了 1234567。这里用的是 group(1),它与 group() 有所不同,后者会输出完整的匹配结果,而前者会输出第一个被 () 包围的匹配结果。假如正则表达式后面还有 () 包括的内容,那么可以依次用 group(2)、group(3) 等来获取。
通用匹配
刚才我们写的正则表达式其实比较复杂,出现空白字符我们就写 匹配,出现数字我们就用 配,这样的工作量非常大。其实完全没必要这么做,因为还有一个万能匹配可以用,那就是.(点星)。其中.(点)可以匹配任意字符(除换行符),(星)代表匹配前面的字符无限次,所以它们组合在一起就可以匹配任意字符了。有了它,我们就不用挨个字符地匹配了。
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello.*Demo$', content)
print(result)
print(result.group())
print(result.span())转义匹配
我们知道正则表达式定义了许多匹配模式,如。匹配除换行符以外的任意字符,但是如果目标字符串里面就包含.,那该怎么办呢?
这里就需要用到转义匹配了,示例如下:
import re
content = '(百度) www.baidu.com'
result = re.match('\(百度\) www\.baidu\.com', content)
print(result)当遇到用于正则匹配模式的特殊字符时,在前面加反斜线转义一下即可。例如。就可以用 . 来匹配,
可以看到,这里成功匹配到了原字符串。
这些是写正则表达式常用的几个知识点,熟练掌握它们对后面写正则表达式匹配非常有帮助。
8.3.2 sub
除了使用正则表达式提取信息外,有时候还需要借助它来修改文本。比如,想要把一串文本中的所有数字都去掉,如果只用字符串的 replace 方法,那就太烦琐了,这时可以借助 sub 方法。示例如下:
import re
content = '54aK54yr5oiR54ix5L2g'
content = re.sub('\d+', '', content)
print(content)8.3.3 compile
前面所讲的方法都是用来处理字符串的方法,最后再介绍一下 compile 方法,这个方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。示例代码如下:
import re
content1 = '2016-12-15 12:00'
content2 = '2016-12-17 12:55'
content3 = '2016-12-22 13:21'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result2 = re.sub(pattern, '', content2)
result3 = re.sub(pattern, '', content3)
print(result1, result2, result3)8.4 httpx
可以爬取HTTP/2.0网站。例如: https://spa16.scrape.center
简单试一下requests
import requests
try:
url = 'https://spa16.scrape.center/'
response = requests.get(url)
print(response.json())
except Exception as e:
print(e)安装httpx
pip install 'httpx[http2]'8.4.1 httpx 基本使用
基本用法和requests差不多
import httpx
response = httpx.get('https://httpbin.org/get')
print(response.status_code)
print(response.headers)
print(response.text)可以看到 “User-Agent”: “python-httpx/0.23.3”。伪装一下Agent信息:
import httpx
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
response = httpx.get('https://httpbin.org/get', headers=headers)
print(response.text)8.4.2 Client对象
httpx中的Client对象类似于requests中的Session对象。
import httpx
with httpx.Client() as client:
response = client.get('https://httpbin.org/get')
print(response)client = httpx.Client()
try:
response = client.get('https://httpbin.org/get')
finally:
client.close()import httpx
url = 'http://httpbin.org/headers'
headers = {'User-Agent': 'my-app/0.0.1'}
with httpx.Client(headers=headers) as client:
r = client.get(url)
print(r.json()['headers']['User-Agent'])8.4.3 支持HTTP 2.0
import httpx
client = httpx.Client(http2=True)
response = client.get(
'https://spa16.scrape.center/')
print(response.text)
print(response.http_version)8.5 other choice
- 各大网站的API
- Chrome Extension